Add documentation based on docusarus for opendbm
This commit is contained in:
11
docs/docs/_markdown-m1-cocoapods.mdx
Normal file
11
docs/docs/_markdown-m1-cocoapods.mdx
Normal file
@@ -0,0 +1,11 @@
|
||||
<details>
|
||||
<summary>Note for Mac M1 users</summary>
|
||||
|
||||
Mac M1 architecture is not directly compatible with Cocoapods. If you encounter issues when installing pods, you can solve it by running:
|
||||
|
||||
- `sudo arch -x86_64 gem install ffi`
|
||||
- `arch -x86_64 pod install`
|
||||
|
||||
These commands install the `ffi` package, to load dynamically-linked libraries and let you run the `pod install` properly, and runs `pod install` with the proper architecture.
|
||||
|
||||
</details>
|
||||
7
docs/docs/_markdown-new-architecture-warning.mdx
Normal file
7
docs/docs/_markdown-new-architecture-warning.mdx
Normal file
@@ -0,0 +1,7 @@
|
||||
:::caution
|
||||
|
||||
This documentation is still **experimental** and details are subject to changes as we iterate. Feel free to share your feedback on the [discussion inside the working group](https://github.com/reactwg/react-native-new-architecture/discussions/8) for this page.
|
||||
|
||||
Moreover, it contains several **manual steps**. Please note that this won't be representative of the final developer experience once the New Architecture is stable. We're working on tools, templates and libraries to help you get started fast on the New Architecture, without having to go through the whole setup.
|
||||
|
||||
:::
|
||||
41
docs/docs/action-units.md
Normal file
41
docs/docs/action-units.md
Normal file
@@ -0,0 +1,41 @@
|
||||
---
|
||||
id: action-units
|
||||
title: Action units
|
||||
---
|
||||
|
||||
Action units (AUs) are individual facial musculature arrangements specified in the [Facial Action Coding System (FACS)](https://en.wikipedia.org/wiki/Facial_Action_Coding_System), combinations of which can account for all possible facial expressions[^1]. OpenDBM outputs framewise values for AU presence and intensity for the following AUs:
|
||||
|
||||
| Action unit number | Description |
|
||||
| ----------- | ----------- |
|
||||
| AU1 | Inner brow raiser |
|
||||
| AU2 | Outer brow raiser |
|
||||
| AU4 | Brow lowerer |
|
||||
| AU5 | Upper lid raiser |
|
||||
| AU6 | Cheek raiser |
|
||||
| AU7 | Lid tightener |
|
||||
| AU9 | Nose wrinkler |
|
||||
| AU12 | Lip corner puller |
|
||||
| AU15 | Lip corner depressor |
|
||||
| AU16 | Lower lip depressor |
|
||||
| AU20 | Lip stretcher |
|
||||
| AU23 | Lip tightener |
|
||||
| AU26 | Jaw drop |
|
||||
|
||||
For each of the AUs in the table above, the following raw variables are calculated:
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_auXXpres` | **Action Unit presence,** where XX refers to the action unit. This is a binary (1/0) variable, where 1 signifies presence of the action unit and 0 signifies its absence as determined by OpenFace. |
|
||||
| `fac_auXXint` | **Action Unit intensity,** where XX refers to the action unit. This is a continuous (0-5) variable, where 0 signifies no presence and 5 signifies maximum presence, as determined by OpenFace. |
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_auXXpres_pct` | **Action Unit presence percentage.** Using the binary vector fac_auXXpres, the percentage of video frames where an AU was present is calculated into this variable. |
|
||||
| `fac_auXXint_mean` | **Action Unit intensity mean.** Mean value of fac_auXXint over the course of the video. |
|
||||
| `fac_auXXint_std` | **Action Unit intensity standard deviation.** Standard deviation of fac_auXXint over the course of the video. |
|
||||
|
||||
|
||||
[^1]: Ekman, R. (1997). What the face reveals: Basic and applied studies of spontaneous expression using the Facial Action Coding System (FACS). Oxford University Press, USA.
|
||||
8
docs/docs/amount-data-needed.md
Normal file
8
docs/docs/amount-data-needed.md
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
id: amount-data-needed
|
||||
title: Amount of Data Needed
|
||||
---
|
||||
|
||||
This is one of the more common questions we get and I’m sorry to say there really isn’t one answer that applies here, as one can imagine. I can point to [some of our work](https://docs.google.com/spreadsheets/u/2/d/1pRBWCCFMbEgZNQzm2Litm3RUQ6glwUwswrqGDePMvh0/edit?usp=drive_web&ouid=112869092988495381590) using OpenDBM and you can look at the sample sizes in there (which are fairly small). But here are some truths. More data is of course always better; no denying that. Video and audio data, though, is quite rich, and the length of behavior one would need to see effects (in our experience) is not hours, but minutes and sometimes just seconds. Importantly, this differs depending on the patient population and the behaviors during which the measures are being quantified. The only real advice we can provide in this matter is to search the literature and see what it says. In most cases, there is precedent to lean on. That can help with selecting the number of patients, time points, and length of video/audio needed to see effects.
|
||||
|
||||
Good luck!
|
||||
22
docs/docs/audio-guidelines.md
Normal file
22
docs/docs/audio-guidelines.md
Normal file
@@ -0,0 +1,22 @@
|
||||
---
|
||||
id: audio-guidelines
|
||||
title: Audio Guidelines
|
||||
---
|
||||
|
||||
Similar to video, the assumption here is that it is the voice and speech of a patient that is being characterized. OpenDBM calculates acoustic measures from the sound wave that it is getting. So, if there is any sound in the audio file that is not the patient’s voice, OpenDBM does not separate that out, and any subsequent measurements (think: the loudness of the sound, frequency of the waveform, and other acoustic features like the harmonics to noise ratio) will be from of all the sound in the audio file––and not just the patient’s voice. Similarly, if our objective is to characterize aspects of the speech, OpenDBM is transcribing all the speech that it can hear. So, if more than one person is speaking in the audio file, you’re calculating variables from all of that speech––not just the patient’s. Below are some points to take into consideration.
|
||||
|
||||
## Empty/quiet spaces
|
||||
|
||||
If there is empty space at the beginning and end of an audio file, it is advised that the file is cropped at the head and the tail to ensure that the empty space does not contribute to downstream calculations. However, this does not mean that all empty space during speech should be cropped out considering those pauses in speech may actually be biomarkers of health and functioning. However, if the user's audio file contains separate sections of speech, then it is recommended that the file is trimmed accordingly.
|
||||
|
||||
## Background noise
|
||||
|
||||
Given the package will process variables from any audio that is inputted, that includes any background noise that may be part of the file. Background noise will lead to a lower signal-to-noise ratio for all audio marker calculations and should be minimized whenever possible. If an audio file has sustained background noise (e.g. a fan, a murmur in a room), it will affect the accuracy of the calculations. Future versions of this package may conduct additional steps to remove background noise but for now, the user must be cognizant of how other sounds in the audio file may be impacting the measurements.
|
||||
|
||||
## Video data quality
|
||||
|
||||
Please be cognizant of data quality. This includes ensuring that the face is close enough to the camera that individual features are distinguishable, that lighting is consistent across the face e.g. there are no strong shadows, etc. that are going across the face, which could affect the calculations. It is also important that the entirety of the face is in the frame, which can sometimes be an issue if the face is too close to the camera e.g. if the individual is recording on a smartphone front-facing camera and brings it close to their face to speak.
|
||||
|
||||
## Persons per audio
|
||||
|
||||
Similar to Section 6.2.2, OpenDBM’s assumption is that only one person is represented in the audio. Hence, if the audio contains the voice and/or speech of persons other than the individual whose behavior the user is trying to measure, then it is the user’s responsibility to crop out those parts of the audio. In such cases, the user can crop out all relevant sections, save them separately, and process them separately as individual files––or they can concatenate them after cropping and process them as one file. In either case, the final measurements are not affected, so we suggest doing whatever is more convenient and requires less manual work.
|
||||
19
docs/docs/audio-intensity.md
Normal file
19
docs/docs/audio-intensity.md
Normal file
@@ -0,0 +1,19 @@
|
||||
---
|
||||
id: audio-intensity
|
||||
title: Audio Intensity
|
||||
---
|
||||
|
||||
Audio intensity is the loudness of a sound, measured in decibels (dB).
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_int` | **Audio intensity.** Frame-wise intensity of the audio file, measured in dB. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_int_mean` | **Audio intensity mean.** Mean of `aco_int` across the audio file. |
|
||||
| `aco_int_std` | **Audio intensity standard deviation.** Standard deviation of `aco_int` across the audio file. |
|
||||
376
docs/docs/basic-usage.md
Normal file
376
docs/docs/basic-usage.md
Normal file
@@ -0,0 +1,376 @@
|
||||
---
|
||||
id: basic-usage
|
||||
title: Basic Usage
|
||||
---
|
||||
|
||||
|
||||
|
||||
#### Prerequisites read
|
||||
* [Dependencies Installation](dependencies-installation)
|
||||
* [OpenFace Installation](openface-docker-installation)
|
||||
* Make sure to install the distribution package first.
|
||||
|
||||
|
||||
|
||||
|
||||
```commandline
|
||||
pip install opendbm
|
||||
```
|
||||
|
||||
In this section, we are gonna show the basic instruction on how to get biomarker variable from OpenDBM API
|
||||
|
||||
```python
|
||||
from opendbm import Movement
|
||||
|
||||
# code below is how to access to other dbm groups
|
||||
# from opendbm import FacialActivity, VerbalAcoustics, Speech
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
path = "movement_video_test.mp4"
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
#initiate the model
|
||||
model = Movement()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
#Feed input data to the model
|
||||
model.fit(path)
|
||||
```
|
||||
|
||||
|
||||
After we processed the data with our model, now we can get all biomarker variables related to the Movement category
|
||||
|
||||
|
||||
```python
|
||||
#Get facial tremor
|
||||
tremor = model.get_facial_tremor()
|
||||
tremor.to_dataframe().T
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
<div>
|
||||
|
||||
<table border="1" class="dataframe" style={{width:'50%',}}>
|
||||
<thead>
|
||||
<tr style={{textAlign:'right',}}>
|
||||
<th></th>
|
||||
<th>0</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>fac_features_mean_5</th>
|
||||
<td>8.594771</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_5</th>
|
||||
<td>3.87593</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_5</th>
|
||||
<td>0.728575</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_5</th>
|
||||
<td>0.254649</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_12</th>
|
||||
<td>3.719481</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_12</th>
|
||||
<td>2.806784</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_12</th>
|
||||
<td>0.723145</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_12</th>
|
||||
<td>0.456196</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_8</th>
|
||||
<td>6.721486</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_8</th>
|
||||
<td>3.586131</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_8</th>
|
||||
<td>0.825251</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_8</th>
|
||||
<td>0.391167</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_48</th>
|
||||
<td>2.860846</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_48</th>
|
||||
<td>2.174091</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_48</th>
|
||||
<td>0.86145</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_48</th>
|
||||
<td>0.646405</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_54</th>
|
||||
<td>3.678142</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_54</th>
|
||||
<td>2.669815</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_54</th>
|
||||
<td>0.886973</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_54</th>
|
||||
<td>0.578275</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_28</th>
|
||||
<td>0.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_28</th>
|
||||
<td>0.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_28</th>
|
||||
<td>0.677184</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_28</th>
|
||||
<td>1.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_51</th>
|
||||
<td>0.765473</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_51</th>
|
||||
<td>0.54762</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_51</th>
|
||||
<td>0.750383</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_51</th>
|
||||
<td>0.897752</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_66</th>
|
||||
<td>1.971278</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_66</th>
|
||||
<td>1.49907</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_66</th>
|
||||
<td>0.938139</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_66</th>
|
||||
<td>0.776121</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_features_mean_57</th>
|
||||
<td>2.70601</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_tremor_median_57</th>
|
||||
<td>2.019033</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_disp_median_57</th>
|
||||
<td>0.988482</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>fac_corr_57</th>
|
||||
<td>0.713824</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>error_reason</th>
|
||||
<td></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
##Get Eye Blink
|
||||
eye_blink = model.get_eye_blink()
|
||||
eye_blink.to_dataframe()
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
<div>
|
||||
|
||||
<table border="1" class="dataframe" style={{width:'50%',}}>
|
||||
<thead>
|
||||
<tr style={{textAlign:'right',}}>
|
||||
<th></th>
|
||||
<th>mov_blink_ear</th>
|
||||
<th>vid_dur</th>
|
||||
<th>fps</th>
|
||||
<th>mov_blinkframes</th>
|
||||
<th>mov_blinkdur</th>
|
||||
<th>dbm_master_url</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>0</th>
|
||||
<td>0.124566</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>19</td>
|
||||
<td>0.655172</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>1</th>
|
||||
<td>0.125343</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>49</td>
|
||||
<td>1.034483</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>2</th>
|
||||
<td>0.108713</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>120</td>
|
||||
<td>2.448276</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>3</th>
|
||||
<td>0.097553</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>169</td>
|
||||
<td>1.689655</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>4</th>
|
||||
<td>0.111874</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>241</td>
|
||||
<td>2.482759</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>5</th>
|
||||
<td>0.077082</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>328</td>
|
||||
<td>3.000000</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>6</th>
|
||||
<td>0.124804</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>387</td>
|
||||
<td>2.034483</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>7</th>
|
||||
<td>0.082149</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>506</td>
|
||||
<td>4.103448</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>8</th>
|
||||
<td>0.083041</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>550</td>
|
||||
<td>1.517241</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>9</th>
|
||||
<td>0.148836</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>687</td>
|
||||
<td>4.724138</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>10</th>
|
||||
<td>0.099926</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>734</td>
|
||||
<td>1.620690</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>11</th>
|
||||
<td>0.083078</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>809</td>
|
||||
<td>2.586207</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>12</th>
|
||||
<td>0.124501</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>847</td>
|
||||
<td>1.310345</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>13</th>
|
||||
<td>0.149668</td>
|
||||
<td>33.877313</td>
|
||||
<td>29</td>
|
||||
<td>931</td>
|
||||
<td>2.896552</td>
|
||||
<td>movement_video_test.mp4</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
</div>
|
||||
115
docs/docs/beginner-installation.md
Normal file
115
docs/docs/beginner-installation.md
Normal file
@@ -0,0 +1,115 @@
|
||||
---
|
||||
id: beginner-installation
|
||||
title: Installation for Beginner
|
||||
description: Beginner Installation
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
import ThemedImage from '@theme/ThemedImage';
|
||||
|
||||
This chapter should help with getting OpenDBM set up on your system. OpenDBM is meant to be accessible to everyone––including folks who are not necessarily technical. If you feel comfortable with terminal, git, and docker, skip to Section 2.2. For everyone else, Section 2.1 accomplishes the same steps in Section 2.2––just with a lot more guidance along the way.
|
||||
|
||||
## OpenDBM installation for beginners
|
||||
|
||||
Alright, you want to measure digital biomarkers from your data but all of this pretty much just feels like magic right now. No worries, you do not need to know how to code to use OpenDBM. We’ll break it down for you. Let’s get started.
|
||||
|
||||
### Install GitHub and clone OpenDBM
|
||||
|
||||
GitHub is just where we––and most other people––store code and other stuff. They do so in ‘repositories’ or ‘repos,’ which are basically just folders of code (and other stuff). The first thing you’re going to do is clone i.e. copy/download the OpenDBM repo from GitHub into a folder on your computer. You can do this manually, even though that’s lame, or by using the GitHub CLI.
|
||||
|
||||
<Tabs>
|
||||
<TabItem value="manual" label="The manual way" default>
|
||||
|
||||
You can manually clone the <a href="https://github.com/AiCure/open_dbm">repo</a> by finding the Download ZIP button shown below:
|
||||
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/githubodbm.png" width="1000" alt="Screenshot of OpenDBM Github page" />
|
||||
<figcaption>Screenshot of OpenDBM Github page.</figcaption>
|
||||
</figure>
|
||||
|
||||
Then, you can save the (unzipped) folder anywhere you want on your computer. Make sure it’s an easy location since you’ll have to navigate to it a lot to use OpenDBM.
|
||||
</TabItem>
|
||||
<TabItem value="better" label="The better way">
|
||||
|
||||
GitHub also has a command line interface (CLI) that allows you to conduct a lot of GitHub-related operations straight from your **Terminal** (if you’re on Mac/Linux) or **Command Prompt** (if you’re on a PC). This is really helpful down the road for a bunch of reasons.
|
||||
|
||||
To get started with GitHub CLI, just follow the instructions [they’ve laid out](https://github.com/cli/cli#installation) on their website.
|
||||
|
||||
Once you’re done with that, you can use the GitHub CLI to clone OpenDBM.
|
||||
|
||||
But first, let’s open **Terminal / Command Prompt** and navigate to the folder where you want to store the OpenDBM code. If you have never used Terminal or Command Prompt before, no worries: These are good links for quick primers on navigating folders in [Mac](https://computers.tutsplus.com/tutorials/navigating-the-terminal-a-gentle-introduction--mac-3855) and [Windows](https://riptutorial.com/cmd/example/8646/navigating-in-cmd).
|
||||
|
||||
Once you’re in the folder where you want to clone OpenDBM, you can use git clone by pasting the command shown below into **Terminal / Command Prompt** and hitting Enter. Once you do that, it’ll download the OpenDBM code from GitHub onto your system (this will take a little bit).
|
||||
|
||||
```bash
|
||||
git clone https://github.com/AiCure/open_dbm.git
|
||||
```
|
||||
|
||||
Once that’s done, you should be able to see a folder in your **Finder / File Explorer** (or from within **Terminal / Command Prompt**, of course) called open_dbm with all the contents you saw listed on the GutHub repo. Now we’re getting somewhere.
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
### Install Docker and build your images
|
||||
|
||||
Anytime you install a proper application on your computer (e.g. let’s say you download Spotify or Skype), it will most likely come with all the things it needs to be able to run successfully. I’m sorry to say this is absolutely not the case when downloading software from GitHub.
|
||||
|
||||
As has been mentioned before, OpenDBM is built ‘on top of’ a bunch of existing open source tools. That means it depends on a lot of other software to function and do the things it needs to do. And the user is responsible for scouring the internet for OpenDBM’s ‘dependencies,’ listed in the requirements.txt file that comes with it, and installing each and every one of them.
|
||||
|
||||
Normally, that’s exactly what you’d have to do––and we wouldn’t feel bad about it; it’s just how things are. But, we found that some of OpenDBM’s critical dependencies, such as OpenFace, are actually quite finicky to install––even for pros. So, we’ve come up with a solution.
|
||||
|
||||
We’re happy to report that OpenDBM does indeed come with all its dependencies. But there are a few extra steps involved to make that work––and it requires learning a bit about Docker.
|
||||
|
||||
#### Get familiar with docker
|
||||
|
||||
As is so wonderfully summarized on [this website](https://docs.microsoft.com/en-us/dotnet/architecture/microservices/container-docker-introduction/docker-defined), “Docker is an open-source project for automating the deployment of applications as portable, self-sufficient containers that can run on the cloud or on-premises. Docker is also a company that promotes and evolves this technology.”
|
||||
|
||||
Basically, it packages up all the dependencies that you would otherwise have to install into a ‘container,’ where all dependencies conveniently come pre-installed. So, as long as you’re using OpenDBM from within that container, you need not worry about all the dependencies.
|
||||
|
||||
This will all make more sense in a bit.
|
||||
|
||||
So, follow the [instructions on the Docker website](https://docs.docker.com/desktop/) to install Docker on your system. We recommend you use the latest stable version. Once downloaded and installed, launch Docker, open Terminal / Command Prompt, and check the version to ensure that Docker is properly installed and running:
|
||||
|
||||
**NOTE for Windows User**: Please use the instruction [here](openface-docker-installation#if-you-havent-heres-the-instruction-on-how-to-install-docker) to install docker and/or enable WSL 2 as Docker Integration
|
||||
|
||||
```bash
|
||||
% docker --version
|
||||
Docker version 19.03.12, build 48a66213fe
|
||||
```
|
||||
|
||||
If you’re on a Mac, Docker should also show up in your Menu bar (I would give a screenshot for PC too but unfortunately I don’t have one). Make sure it states ‘Docker Desktop is running’
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/docker_running.png" width="500" alt="Screenshot of Docker running" />
|
||||
<figcaption>Screenshot of Docker running.</figcaption>
|
||||
</figure>
|
||||
|
||||
#### Build Docker image
|
||||
|
||||
When you cloned OpenDBM onto your computer, it contained a Docker file (you can see for yourself; it’s called Dockerfile). This file is basically a set of instructions that will create the docker image upon which the aforementioned Docker container will be built. Don’t sweat the details; you can build the Docker image just by using a single command.
|
||||
|
||||
While in **Terminal / Command Prompt**, navigate to the inside of the folder where you cloned OpenDBM. So, if you cloned OpenDBM in **/Users/JohnWick**, then **cd** into the **open_dbm** folder so that when you type the **pwd** command, you should see that you’re in **/Users/JohnWick/open_dbm**. From here, run the following command:
|
||||
|
||||
```bash
|
||||
% docker build --tag dbm .
|
||||
```
|
||||
|
||||
This should set off an installation script to build the docker image. It will take some time to run. On a regular Macbook Pro, that’s around 20-40 minutes to fully execute.
|
||||
|
||||
Once it’s done running, you can run the following command and it should show you the Docker image that you just created.
|
||||
|
||||
```bash
|
||||
% docker images
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
dbm latest 4ad5c2b21553 2 hours ago 4.98GB
|
||||
```
|
||||
|
||||
If you run into any problems here, please use the [Issues](https://github.com/AiCure/open_dbm/issues) tab on the OpenDBM GitHub page to report the error you see and we will try our best to resolve it as soon as possible. We’ve even created an Issue template for you to follow that should pop up automatically.
|
||||
|
||||
Let’s say you don’t run into any issues and everything runs smoothly. You’re… kinda done with installation. You can skip [Installation for Pro](pro-installation). Chapter 3 will go over how to use OpenDBM to calculate digital biomarkers from your data. Good news: That also just requires a single command.
|
||||
|
||||
---
|
||||
|
||||
Now that you’ve covered OpenDBM installation, let’s dive deeper on some of these core modules by looking at [Usage](opendbm-docker-usage).
|
||||
38
docs/docs/behavioral-considerations.md
Normal file
38
docs/docs/behavioral-considerations.md
Normal file
@@ -0,0 +1,38 @@
|
||||
---
|
||||
id: behavioral-considerations
|
||||
title: Behavioral Considerations
|
||||
---
|
||||
|
||||
Individual behavior is one of the more important aspects to consider when calculating digital biomarkers. OpenDBM is blind to the different behaviors the individual is participating in within the video or audio it is processing. For example, if in the same video, the individual is demonstrating spontaneous facial behavior (e.g. responding to an open-ended question) and then later in the video are asked to *make* a face (e.g. being asked to purse their lips, as some patients are during clinical assessments of facial tremor), OpenDBM is going to make its measurements across both behaviors. So, if the user is trying to measure spontaneous emotional expressivity, they really only want to do that in the former case; not the latter. Hence, when processing markers from data using OpenDBM, the user needs to split data by behavior.
|
||||
|
||||
## Splitting behaviors
|
||||
|
||||
The user is most knowledgeable about the data being processed, the experimental paradigm that was used to collect it (or lack thereof), and the different clinically meaningful behaviors that may be present in it. An exhaustive list of different kinds of clinically meaningful behavior is not within the scope of this section; it depends of course on the disease population and the literature that may or may not exist regarding relevant behaviors. Below are examples of some behaviors we’ve learned to analyze separately:
|
||||
|
||||
* Facial behaviors
|
||||
* Spontaneous facial expressivity while resting
|
||||
* Spontaneous facial expressivity while talking
|
||||
* In response to neutral stimuli
|
||||
* In response to valenced stimuli (e.g. talking about positively or negatively valenced images or videos, questions about symptomatology)
|
||||
* Expressions made on cue (e.g. when asked to make a face such as a happy face, sad face, pursed lips, shut eyes)
|
||||
* Facial expressions evoked naturally in response to stimuli (e.g. immediate visual responses such as ‘micro-expressions’ to images, videos, or other stimuli)
|
||||
* Vocal acoustic behaviors
|
||||
* Acoustics of voice during sustained vowel sounds (e.g. say *aah* for a few seconds, say eee for a few seconds––this is super prevalent in the literature).
|
||||
* Acoustics of voice during free speech (e.g. responding to an open-ended question or just generally talking or in conversation)
|
||||
* Speech behaviors
|
||||
* Free speech as part of general, neutrally valenced conversation
|
||||
* Free speech as part of positively or negatively valenced conversation or responding to valenced stimuli (e.g. being asked to speak about a past traumatic experience, image, or video)
|
||||
* Evoked speech when asked to say something (e.g. saying the names of the days of the week or months)
|
||||
* Evoked speech when asked to read something (e.g. reading a passage)
|
||||
* Movement behaviors
|
||||
* Free head movement when resting or speaking
|
||||
* Eye gaze behaviors when looking at social vs. non-social stimuli
|
||||
* Eye gaze behaviors in contexts where saccades could be measured
|
||||
|
||||
As can be deduced from the list above, there are a lot of different kinds of behaviors––and each of them may or may not be relevant depending on the clinical population being studied. For example, we find that measurements of blunted affect in individuals with schizophrenia are much stronger when acquired from elicited expressions (e.g. being asked to make an expressive face) compared to during spontaneous behaviors (e.g. when responding to a question), but that the case is the opposite in individuals with Major Depressive Disorder (please note that this is not a universal truth; just something we’ve observed in our experiments). We can’t comment on which behaviors are best for the user to be able to measure the symptomatology they’re looking for––all we can suggest is diving into past literature to see if there are clues as to what behaviors are best for eliciting the disease’s symptomatology.
|
||||
|
||||
## Analyzing behavioral data
|
||||
|
||||
If the user is working with data that contains different patient behaviors i.e., let’s say they split up a video of a patient participating in free speech and also sustained vowel sounds into two separate videos: a free speech video and a sustained vowel sound video. The amount of digital biomarker variables the user has access to multiplies by the number of behaviors. So––let’s say the user is interested in measuring the mean fundamental frequency (Section 5.2.1) of voice. Now they have two fundamental frequency mean variables: one for free speech, one for sustained vowel sounds. In the data analysis that follows, these can essentially be treated as separate variables.
|
||||
|
||||
There’s an additional point to be made here: Some variables only make sense for certain behaviors. For example, the vocal tremor variable in Section 5.4.3 is only useful in the context of sustained vowel sounds. Even in clinical examinations of vocal tremor, patients are asked to make sustained vowel sounds (i.e. say *aah* out loud for a few seconds) and the tremor in their voice is then assessed subjectively by the interviewer/clinician from that sound. Hence, in some cases, a variable may not be informative if it is not collected from the right kind of behavior. Referencing the example from the previous paragraph, mean fundamental frequency is also more relevant when measured from sustained vowel sounds, whereas its standard deviation may be more relevant during free speech. The user must take such factors into consideration when analyzing digital biomarker data.
|
||||
21
docs/docs/biomaker-variables.md
Normal file
21
docs/docs/biomaker-variables.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
id: biomaker-variables
|
||||
title: Biomaker Variables
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
## Biomaker Variables
|
||||
|
||||
This chapter outlines the entire list of biomarkers that OpenDBM v2.0 calculates.
|
||||
|
||||
For each biomarker, both raw variables and derived variables are calculated. Raw variables are often frame-wise values containing measurements according to the temporal resolution of the inputted file (e.g. happiness expressivity in each frame of video in an inputted video file or audio intensity for each audio frame in an audio file). Derived variables are abstractions of their respective raw variables (e.g. average happiness expressivity across a video or standard deviation of audio intensity over the course of the audio file).
|
||||
|
||||
It is helpful to think of raw variables as quantifications of behavioral characteristics, with derived variables being the ones acting as biomarkers of health and functioning. OpenDBM outputs both raw and derived variables when it is executed. However, it is possible that the user will only need to utilize the derived variable output for their research––unless they are interested in delving deeper into the data and making their own derived variable abstractions.
|
||||
|
||||
All variables are named according to a standard nomenclature. Raw variable names contain two sections, while derived variable names contain three sections. The figure below demonstrates what each section of the variable name, separated by underscores, refers to.
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/biomaker-variables-1.png" width="1000" alt="Description of the standard nomenclature used to name all raw and derived variable outputs from OpenDBM, allowing for determination of variable contents without having to memorize all variable names." />
|
||||
<figcaption>Description of the standard nomenclature used to name all raw and derived variable outputs from OpenDBM, allowing for determination of variable contents without having to memorize all variable names.</figcaption>
|
||||
</figure>
|
||||
11
docs/docs/data-guidelines.md
Normal file
11
docs/docs/data-guidelines.md
Normal file
@@ -0,0 +1,11 @@
|
||||
---
|
||||
id: data-guidelines
|
||||
title: Overview
|
||||
---
|
||||
|
||||
<div className="banner-native-code-required">
|
||||
<h3>OpenDBM Data Guidelines</h3>
|
||||
<p>
|
||||
OpenDBM is meant to be broadly applicable to video and audio data. Given the plethora of possibilities in terms of what that data could contain, it is important to take certain guidelines into consideration before processing your data. This chapter outlines some of those considerations, which should help with experimental design, data organization, and analysis––all while ensuring a high signal to noise ratio.
|
||||
</p>
|
||||
</div>
|
||||
84
docs/docs/dependencies-installation.md
Normal file
84
docs/docs/dependencies-installation.md
Normal file
@@ -0,0 +1,84 @@
|
||||
---
|
||||
id: dependencies-installation
|
||||
title: Dependencies Installation
|
||||
description: 'OpenDBM needs you to install some dependencies before do any pip install'
|
||||
hide_table_of_contents: true
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
This page will help you install the prerequisites for each OS platforms.
|
||||
|
||||
**If you are new to python environment**, the easiest way to get started is with Conda CLI. Conda is an open source package management system and environment management system that runs on Windows, macOS, Linux and z/OS. Conda quickly installs, runs and updates packages and their dependencies. Conda easily creates, saves, loads and switches between environments on your local computer. It was created for Python programs, but it can package and distribute software for any language.
|
||||
|
||||
**If you are already familiar with python environment**, you may to proceed install the dependencies using your <code>python</code> environment
|
||||
|
||||
<Tabs groupId="guide" defaultValue={constants.defaultGuide} values={constants.guides}>
|
||||
<TabItem value="dep-install">
|
||||
|
||||
The instructions are a bit different depending on your development operating system.
|
||||
|
||||
#### Development OS
|
||||
|
||||
<Tabs groupId="os" defaultValue={constants.defaultOs} values={constants.oses} className="pill-tabs">
|
||||
<TabItem value="macos">
|
||||
|
||||
## Install with conda
|
||||
|
||||
```bash
|
||||
conda install -c conda-forge cmake ffmpeg sox
|
||||
```
|
||||
## Standalone installation (without conda)
|
||||
|
||||
```bash
|
||||
brew install cmake
|
||||
brew install sox
|
||||
brew install ffmpeg
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="windows">
|
||||
|
||||
## Install with conda
|
||||
|
||||
```bash
|
||||
conda install -c conda-forge ffmpeg sox dlib
|
||||
```
|
||||
## Standalone installation (without conda)
|
||||
|
||||
> [Install sox guide](https://www.tutorialexample.com/a-step-guide-to-install-sox-sound-exchange-on-windows-10-python-tutorial/)
|
||||
|
||||
> Follow either of this guide to install ffmpeg
|
||||
> * [geeksforgeeks](https://www.geeksforgeeks.org/how-to-install-ffmpeg-on-windows/)
|
||||
> * [wikihow](https://www.wikihow.com/Install-FFmpeg-on-Windows)
|
||||
|
||||
> [Install dlib guide](https://github.com/sachadee/Dlib)
|
||||
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="linux">
|
||||
|
||||
## Install with conda
|
||||
|
||||
```bash
|
||||
conda install -c conda-forge cmake ffmpeg sox
|
||||
```
|
||||
## Standalone installation (without conda)
|
||||
|
||||
```bash
|
||||
sudo apt-get install cmake
|
||||
sudo apt-get install libsndfile1
|
||||
sudo apt-get install ffmpeg
|
||||
sudo apt-get install sox
|
||||
```
|
||||
|
||||
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
|
||||
|
||||
24
docs/docs/derived-variables.md
Normal file
24
docs/docs/derived-variables.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
id: opendbm-docker-output
|
||||
title: Derived Variables
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
## OpenDBM Output
|
||||
|
||||
In the previous chapter, we went over how to process data using OpenDBM and learned that when we do so, we save a folder called **output** in the location we specify. This chapter is all about what’s in that folder and all the wonderful things we can do with it.
|
||||
|
||||
The first thing you’ll see is that the **output** folder is divided into `raw_variables` and `derived_variables`. As Chapter 5 explains, for each biomarker, both **raw variables** and **derived variables** are calculated. Raw variables are often frame-wise values containing measurements according to the temporal resolution of the inputted file (e.g. happiness expressivity in each frame of video in an inputted video file or audio intensity for each audio frame in an audio file). Derived variables are abstractions of their respective raw variables (e.g. average happiness expressivity across a video or standard deviation of audio intensity over the course of the audio file). Chapter 5 goes into more detail and lists all raw and derived biomarker variables. The purpose of this chapter is to first just explain the structure of the data output from OpenDBM.
|
||||
|
||||
## Derived Variables
|
||||
|
||||
For derived variables, a single CSV file is outputted. This CSV file, named derived_output.csv, contains a row for each video/audio file that was inputted. If only a single file was processed, the CSV file will have only one row. If several were inputted, then several rows will be outputted.
|
||||
|
||||
And, in case you forgot what files and/or excel sheets look like, here are some illustrations:
|
||||
<figure>
|
||||
<img src="/docs/assets/derived_var_1.png" width="1000" alt="Screenshot of output file" />
|
||||
<figcaption>Screenshot of output file.</figcaption>
|
||||
</figure>
|
||||
|
||||
Essentially, the derived variables CSV file is the best place to go for most simple analyses. [In this instructional video](https://www.youtube.com/watch?v=QQY_QA1Y5BM), we conduct a sample data analysis in a made-up experiment and use the derived variable output to test effects of a ‘treatment’ on emotional expressivity in the face.
|
||||
36
docs/docs/emotional-expressivity.md
Normal file
36
docs/docs/emotional-expressivity.md
Normal file
@@ -0,0 +1,36 @@
|
||||
---
|
||||
id: emotional-expressivity
|
||||
title: Emotional Expressivity
|
||||
---
|
||||
|
||||
Continuing to lean on FACS, action unit presence and intensity values are used to measure presence and intensity of emotional expressions, given that combinations of different action units refer to individual emotions as outlined in the table below:
|
||||
|
||||
| Emotion | EMO | Action Units |
|
||||
| ----------- | ----------- | ---- |
|
||||
| Happiness | hap | 6 + 12 |
|
||||
| Sadness | sad | 1 + 4 + 15 |
|
||||
| Surprise | sur | 1 +2 + 5 + 26 |
|
||||
| Fear | fea | 1 + 2 + 4 + 5 + 7 + 20 + 26 |
|
||||
| Anger | ang | 4 + 5 + 7 + 23 |
|
||||
| Disgust | dig | 9 + 15 + 16 |
|
||||
| Contempt | con | 12 + 14 |
|
||||
|
||||
For each of the emotions listed in the table above, the tables below list the raw and derived variables that are calculated for each, with EMO in the variable names referring to any of the seven major emotions as per the short forms in the table above.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_EMOpres` | **Emotion presence.** Binary vector indicating the presence/absence of an emotion in each video frame, with presence being 1 if all action units for that emotion are present. |
|
||||
| `fac_EMOintsoft` | **Emotion intensity ‘soft’.** Continuous vector indicating intensity of the emotion in each video frame regardless of whether all action units for that emotion are present. Range is between 0 and 1. |
|
||||
| `fac_EMOinthard` | **Emotion intensity ‘hard’.** Continuous vector indicating intensity of the emotion in each video frame, only providing non-zero value if all action units for that emotion are present. Range is between 0 and 1. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_EMOpres_pct` | **Emotion presence percentage.** Percentage of frames in the video where the emotion was present, as defined by all action units being present for a given emotion. |
|
||||
| `fac_EMOintsoft_mean` | **Emotional expressivity ‘soft’ mean.** Mean of all fac_EMOintsoft values calculated from the video. |
|
||||
| `fac_EMOintsoft_std` | **Emotional expressivity ‘soft’ standard deviation** of all fac_EMOintsoft values calculated from the video.
|
||||
| `fac_EMOinthard_mean` | **Emotional expressivity ‘hard’ mean.** Mean of all fac_EMOinthard values calculated from the video. |
|
||||
|
||||
24
docs/docs/eye-blink-behavior.md
Normal file
24
docs/docs/eye-blink-behavior.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
id: eye-blink-behavior
|
||||
title: Eye Blink Behavior
|
||||
---
|
||||
|
||||
Eye blinks are measured by first calculating a variable called eye aspect ratio (EAR), which we get from [here](http://dlib.net/face_landmark_detection.py.html), and is basically just a quantification of how open the eye is. Over the course of a video, the EAR ends up being a vector whose troughs most likely signify individual eye blinks. The troughs are identified using a *find peaks* function and for each trough, the EAR value is outputted along with the other raw variables described below.
|
||||
|
||||
### Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_blink_ear` | **Eye aspect ratio** i.e. a vector derived from [this model](http://dlib.net/face_landmark_detection.py.html) at points in the video where an eye blink was detected. |
|
||||
| `mov_blinkframe` | **Eye blink times** are indices of the video frames where an eye blink was detected. |
|
||||
| `mov_blinkdur` | **Durations between blinks** is the time spanned between the current blink and the previous blink in seconds. |
|
||||
|
||||
### Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_blink_ear_mean` | **Eye aspect ratio mean** i.e. the mean of the vector `mov_blink_ear`. |
|
||||
| `mov_blink_ear_std` | **Eye aspect ratio standard deviation** i.e. the standard deviation of the vector `mov_blink_ear`. |
|
||||
| `mov_blink_count` | **Number of blinks** measured over the course of the video. |
|
||||
| `mov_blinkdur_mean` | **Mean duration between eye blinks** measured in seconds. |
|
||||
| `mov_blinkdur_std` | **Standard deviation of duration between eye blinks** measured in seconds. |
|
||||
40
docs/docs/eye-gaze-directionality.md
Normal file
40
docs/docs/eye-gaze-directionality.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
id: eye-gaze-directionality
|
||||
title: Eye Gaze Directionality
|
||||
---
|
||||
|
||||
Eye gaze directionality is another output we get from OpenFace. The variables below allow for measurements of eye gaze behavior.
|
||||
|
||||
### Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_lefteyex` | x coordinate of the left eye at the current video frame. |
|
||||
| `mov_lefteyey` | y coordinate of the left eye at the current video frame. |
|
||||
| `mov_lefteyez` | z coordinate of the left eye at the current video frame. |
|
||||
| `mov_righteyex` | x coordinate of the right eye at the current video frame. |
|
||||
| `mov_righteyey` | y coordinate of the right eye at the current video frame. |
|
||||
| `mov_righteyez` | z coordinate of the right eye at the current video frame. |
|
||||
| `mov_leyedisp` | **Euclidean displacement in the left eye gaze** at the current video frame; this tells the overall movement in eye gaze direction in each frame. |
|
||||
| `mov_reyedisp` | **Euclidean displacement in the right eye gaze** at the current video frame; this tells the overall movement in eye gaze direction in each frame. |
|
||||
|
||||
### Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_lefteyex_mean` | **Mean x coordinate of the left eye** i.e. the average of the vector `mov_lefteyex`. |
|
||||
| `mov_lefteyex_std` | **Standard deviation of x coordinate of the left eye** i.e. the standard deviation of the vector `mov_lefteyex`. |
|
||||
| `mov_lefteyey_mean` | **Mean y coordinate of the left eye** i.e. the average of the vector `mov_lefteyey`. |
|
||||
| `mov_lefteyey_std` | **Standard deviation of y coordinate of the left eye** i.e. the standard deviation of the vector `mov_lefteyey`. |
|
||||
| `mov_lefteyez_mean` | **Mean z coordinate of the left eye** i.e. the average of the vector `mov_lefteyez`. |
|
||||
| `mov_lefteyez_std` | **Standard deviation of z coordinate of the left eye** i.e. the standard deviation of the vector `mov_lefteyez`. |
|
||||
| `mov_righteyex_mean` | **Mean x coordinate of the right eye** i.e. the average of the vector `mov_righteyex`. |
|
||||
| `mov_righteyex_std` | **Standard deviation of x coordinate of the right eye** i.e. the standard deviation of the vector `mov_righteyex`. |
|
||||
| `mov_righteyey_mean` | **Mean y coordinate of the right eye** i.e. the average of the vector `mov_righteyey`. |
|
||||
| `mov_righteyey_std` | **Standard deviation of y coordinate of the right eye** i.e. the standard deviation of the vector `mov_righteyey`. |
|
||||
| `mov_righteyez_mean` | **Mean z coordinate of the right eye** i.e. the average of the vector `mov_righteyez`. |
|
||||
| `mov_righteyez_std` | **Standard deviation of z coordinate of the right eye** i.e. the standard deviation of the vector `mov_righteyez`. |
|
||||
| `mov_leyedisp_mean` | **Mean euclidean displacement in the left eye gaze** over the course of the video. |
|
||||
| `mov_leyedisp_std` | **Standard deviation of euclidean displacement in the left eye gaze** over the course of the video. |
|
||||
| `mov_reyedisp_mean` | **Mean euclidean displacement in the right eye gaze** over the course of the video. |
|
||||
| `mov_reyedisp_std` | **Standard deviation of euclidean displacement in the right eye gaze** over the course of the video. |
|
||||
8
docs/docs/facial-activity.md
Normal file
8
docs/docs/facial-activity.md
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
id: facial-activity
|
||||
title: Facial Activity
|
||||
---
|
||||
|
||||
Facial activity biomarkers relate to visually observable characteristics of the face i.e. movements and arrangements of facial musculature that can––for example––comprise emotional expressions. All facial features are acquired through use of the [OpenFace software library](https://cmusatyalab.github.io/openface/).
|
||||
|
||||
Along with everything else, OpenFace outputs ‘confidence scores’ that delineate how confident it is that it is indeed seeing a face in an image from a video. If the confidence score for an image frame is below 80%, we do not process any facial activity variables for those frames and the framewise raw variable output does not contain values. All derived facial variables that are then calculated from the raw variables only reflect image frames where the confidence was >80%.
|
||||
28
docs/docs/facial-asymmetry.md
Normal file
28
docs/docs/facial-asymmetry.md
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
id: facial-asymmetry
|
||||
title: Facial Asymmetry
|
||||
---
|
||||
|
||||
Using facial landmark detection described in Section 5.1.1, an additional measurement that is made is that of facial asymmetry. Frame-wise and overall asymmetry in landmarks on the left vs. right side of the face is quantified and saved in the following raw and derived variables.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_asymmaskmouth` | **Mouth asymmetry.** Frame-wise asymmetry in the mouth area. |
|
||||
| `fac_asymmaskeye` | **Eye asymmetry.** Frame-wise asymmetry in the eye area. |
|
||||
| `fac_asymmaskeyebrow` | **Eyebrow asymmetry.** Frame-wise asymmetry in the Eyebrow area. |
|
||||
| `fac_asymmaskcom` | **Overall asymmetry.** Frame-wise asymmetry across the face. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_asymmaskmouth_mean` | **Mouth asymmetry mean** across the video. |
|
||||
| `fac_asymmaskmouth_std` | **Mouth asymmetry standard deviation** across the video. |
|
||||
| `fac_asymmaskeye_mean` | **Eye asymmetry mean** across the video. |
|
||||
| `fac_asymmaskeye_std` | **Eye asymmetry standard deviation** across the video. |
|
||||
| `fac_asymmaskeyebrow_mean` | **Eyebrow asymmetry mean** across the video. |
|
||||
| `fac_asymmaskeyebrow_std` | **Eyebrow asymmetry standard deviation** across the video. |
|
||||
| `fac_asymmaskcom_mean` | **Overall asymmetry mean** across the video. |
|
||||
| `fac_asymmaskcom_std` | **Overall asymmetry standard deviation** across the video. |
|
||||
27
docs/docs/facial-landmark.md
Normal file
27
docs/docs/facial-landmark.md
Normal file
@@ -0,0 +1,27 @@
|
||||
---
|
||||
id: facial-landmark
|
||||
title: Facial Landmark
|
||||
---
|
||||
|
||||
Facial landmarks refer to specific regions of the face, with x, y, and z coordinates for each facial landmark variable indicating where in the image frame that specific region of the face is located.
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/facial-landmark-1.png" width="500" alt="Visual representation of the facial landmarks calculated by OpenDBM, which relies on OpenFace and OpenCV for its measurements." />
|
||||
<figcaption>Visual representation of the facial landmarks calculated by OpenDBM, which relies on OpenFace and OpenCV for its measurements.</figcaption>
|
||||
</figure>
|
||||
|
||||
OpenDBM calculates overall change in facial landmark positioning and in doing so measures facial musculature movements at the level of individual facial landmarks. Individual movement of a total of 68 facial landmarks is measured using the raw and derived variables listed in the tables below.
|
||||
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_lmkXXdisp` | **Landmark displacement.** Frame-wise change in landmark positioning i.e. the euclidean distance in the xyz plane, where XX can be any number between 01 and 68, referring to all individual facial landmarks. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_lmkXXdisp_mean` | **Landmark displacement mean.** The mean value of fac_lmkXXdisp for the inputted video. |
|
||||
| `fac_lmkXXdisp_std` | **Landmark displacement standard deviation.** The standard deviation value of fac_lmkXXdisp for the inputted video. |
|
||||
18
docs/docs/facial-tremor.md
Normal file
18
docs/docs/facial-tremor.md
Normal file
@@ -0,0 +1,18 @@
|
||||
---
|
||||
id: facial-tremor
|
||||
title: Facial Tremor
|
||||
---
|
||||
|
||||
Measurements of facial tremor are acquired by looking at movements in individual facial landmarks as shown in Section 5.1.1. They are separated into measurements of tremor at individual landmarks of the face, which allows for specific calculation of tremor in particular areas of the face but can also be averaged to measure tremor in larger areas of the face or the entire face as a whole.
|
||||
|
||||
### Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_tremor_median_X` | **Amount of tremor detected** in a specific frame, with X referring to the facial landmark number. |
|
||||
|
||||
### Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_tremor_median_X_mean` | **Mean amount of tremor detected** over the course of the video, with X referring to the facial landmark number. |
|
||||
24
docs/docs/formant-frequencies.md
Normal file
24
docs/docs/formant-frequencies.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
id: formant-frequencies
|
||||
title: Formant Frequencies
|
||||
---
|
||||
|
||||
## Formant Frequencies (f<sub>1-4</sub>)
|
||||
|
||||
Formants are spectral peaks in the sound spectrum that are typically distributed in bands across different frequencies[^1]. OpenDBM outputs values for the first four formants (f<sub>1-4</sub>), with N in the variable names in the tables below referring to the formant number.
|
||||
|
||||
|
||||
[^1]: https://en.wikipedia.org/wiki/Fundamental_frequency
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_fmN` | **Formant frequency.** Frame-wise formant frequency (f<sub>N</sub>) measurements, with N being 1, 2, 3, or 4, referring to the 1st, 2nd, 3rd, or 4th formant respectively. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_fmN_mean` | **Formant frequency mean.** Mean of the Nth formant (f<sub>N</sub>) across all audio frames. |
|
||||
| `aco_fmN_std` | **Formant frequency standard deviation.** Standard deviation of the Nth formant (f<sub>N</sub>) across all audio frames. |
|
||||
22
docs/docs/fundamental-frequency.md
Normal file
22
docs/docs/fundamental-frequency.md
Normal file
@@ -0,0 +1,22 @@
|
||||
---
|
||||
id: fundamental-frequency
|
||||
title: Fundamental Frequency
|
||||
---
|
||||
|
||||
The fundamental frequency (f<sub>0</sub>) is the lowest frequency of a periodic waveform, measured in Hertz (Hz). It is the greatest common divisor of all the frequency components contained in a signal.[^1]
|
||||
|
||||
|
||||
[^1]: https://en.wikipedia.org/wiki/Fundamental_frequency
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_ff` | **Fundamental frequency.** Frame-wise fundamental frequency values in Hz. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_ff_mean` | **Fundamental frequency mean.** Mean of aco_ff across the audio file. |
|
||||
| `aco_ff_std` | **Fundamental frequency standard deviation.** Standard deviation of aco_ff across the audio file. |
|
||||
21
docs/docs/glottal-to-noise-excitation-ratio.md
Normal file
21
docs/docs/glottal-to-noise-excitation-ratio.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
id: glottal-to-noise-excitation-ratio
|
||||
title: Glottal-to-noise Excitation Ratio (GNE)
|
||||
---
|
||||
|
||||
Glottal-to-noise excitation ratio, as introduced by Michaelis and colleagues[^1], is an indirect measure of breathiness, indicating whether a “given voice signal originates from vibrations in the vocal folds or from turbulent noise generated in the vocal tract.”
|
||||
|
||||
[^1]: Michaelis, D., Gramss, T., & Strube, H. W. (1997). Glottal-to-noise excitation ratio–a new measure for describing pathological voices. Acta Acustica united with Acustica, 83(4), 700-706.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_gne` | **Glottal-to-noise excitation ratio.** Frame-wise measurements of glottal-to-noise excitation ratio. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_gne_mean` | **Glottal-to-noise excitation ratio mean.** Mean of `aco_hnr` across the audio file. |
|
||||
| `aco_gne_std` | **Glottal-to-noise excitation ratio standard deviation.** Standard deviation of `aco_gne` across the audio file. |
|
||||
21
docs/docs/harmonics-to-noise-ratio.md
Normal file
21
docs/docs/harmonics-to-noise-ratio.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
id: harmonics-to-noise-ratio
|
||||
title: Harmonics-to-noise Ratio (HNR)
|
||||
---
|
||||
|
||||
The harmonics-to-noise ratio (HNR), a common measurement of aspiration, quantifies the amount of additive noise in the voice signal.[^1]
|
||||
|
||||
[^1]: Ferrand, C. T. (2002). Harmonics-to-noise ratio: an index of vocal aging. Journal of voice, 16(4), 480-487.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_hnr` | **Harmonics-to-noise ratio.** Frame-wise measurements of harmonics-to-noise ratio. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_hnr_mean` | **Harmonics-to-noise ratio mean.** Mean of `aco_hnr` across the audio file. |
|
||||
| `aco_hnr_stdev` | **Harmonics-to-noise ratio standard deviation.** Standard deviation of `aco_hnr` across the audio file. |
|
||||
42
docs/docs/head-movement.md
Normal file
42
docs/docs/head-movement.md
Normal file
@@ -0,0 +1,42 @@
|
||||
---
|
||||
id: head-movement
|
||||
title: Head Movement
|
||||
---
|
||||
|
||||
## Movement
|
||||
|
||||
OpenDBM focuses on computer vision-based measurements of movement. This refers to movement that can be detected in videos of individuals, focusing primarily on their head and face. Future versions of OpenDBM will hopefully include additional measurements as well.
|
||||
|
||||
## Head Movement
|
||||
|
||||
Head movement is measured in two ways. The first is a Euclidean measurement i.e. in the * * plane. The position of the head in x, y, and z coordinates is calculated as a raw variable in each frame. These raw variables are then used to measure overall head movement in the *xyz* plane.
|
||||
|
||||
The second method to measure head movement is by measuring angular changes in radians. The position of the head’s pitch, roll, and yaw is calculated as a raw variable in each frame. These variables are then used to measure overall change in head pitch, yaw, and roll as derived variables.
|
||||
|
||||
Only image frames where the OpenFace confidence score is greater than 20% are used for all downstream calculations (OpenFace confidence scores were explained in Section 5.1)
|
||||
|
||||
### Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_headvel` | **Euclidean head movement.** Frame-wise Euclidean displacement of the head in the xyz plane. |
|
||||
| `mov_hposepitch` | **Head pitch angle.** Frame-wise pitch angle of the head. |
|
||||
| `mov_hposeyaw` | **Head yaw angle.** Frame-wise yaw angle of the head. |
|
||||
| `mov_hposeroll` | **Head roll angle.** Frame-wise roll angle of the head. |
|
||||
| `mov_hposedist` | **Angular head movement.** Frame-wise change in head angle, combining pitch, yaw, and roll movements. |
|
||||
|
||||
### Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_headvel_mean` | **Euclidean head movement mean.** Mean of `mov_headvel` across the video in mm/frame. |
|
||||
| `mov_headvel_std` | **Euclidean head movement standard deviation.** Standard deviation of `mov_headvel` across the video. |
|
||||
| `mov_hposepitch_mean` | **Head pitch movement mean.** Mean of the pitch angle of the head across the video. |
|
||||
| `mov_hposepitch_std` | **Head pitch movement standard deviation.** Standard deviation of the pitch angle of the head across the video i.e. amount of head movement in the pitch direction. |
|
||||
| `mov_hposeyaw_mean` | **Head yaw movement mean.** Mean of the yaw angle of the head across the video. |
|
||||
| `mov_hposeyaw_std` | **Head yaw movement standard deviation.** Standard deviation of the yaw angle of the head across the video i.e. amount of head movement in the yaw direction. |
|
||||
| `mov_hposeroll_mean` | **Head roll movement mean.** Mean of the roll angle of the head across the video. |
|
||||
| `mov_hposeroll_std` | **Head roll movement standard deviation.** Standard deviation of the roll angle of the head across the video i.e. amount of head movement in the roll direction. |
|
||||
| `mov_hposedist_mean` | **Angular head movement mean.** Mean of `mov_hposedist` across the video. |
|
||||
| `mov_hposedist_std` | **Angular head movement standard deviation.** Standard deviation of mov_hposedist across the video. |
|
||||
|
||||
54
docs/docs/introduction.md
Normal file
54
docs/docs/introduction.md
Normal file
@@ -0,0 +1,54 @@
|
||||
---
|
||||
id: getting-started
|
||||
title: Introduction
|
||||
description: This helpful guide lays out the prerequisites for learning OpenDBM, using these docs, and setting up your environment.
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
<div className="content-banner">
|
||||
<p>
|
||||
Welcome to the very start of your OpenDBM journey! If you're looking for straight install and usage instructions, you can move to <a href="dependencies-installation">this section</a>. Continue reading for an introduction of OpenDBM before installing.
|
||||
</p>
|
||||
<img className="content-banner-img" src="../docs/assets/aicure_white.png" alt=" " />
|
||||
</div>
|
||||
|
||||
OpenDBM is an open-source tool for measurement of digital biomarkers from video and audio of patient behavior. It is built on existing software packages used to quantify behavioral characteristics. Our goal is to increase accessibility of methods in digital phenotyping to researchers trying to understand the relationship between neuropsychiatric illnesses and their behavioral manifestations.
|
||||
|
||||
Through OpenDBM, a user can objectively and sensitively measure behavioral characteristics such as facial activity, vocal acoustics, characteristics of speech, patterns of movement, and oculomotion. From those behavioral characteristics, they can measure clinically meaningful symptomatology such as emotional expressivity, prosody of voice, valence of speech, and severity of tremor––among many others.
|
||||
|
||||
We hope to encourage researchers to use objective quantification of symptomatology in their analyses and to inspire them to contribute their own code, leading to a central repository of methods. Only by doing so can academia, healthcare, and industry collaborate effectively on the advancement of digital measurement of health and create access to novel tools in digital phenotyping.
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
To work with OpenDBM, you will need to have an understanding of Python fundamentals. If you’re new to Python or need a refresher, you can [dive in](https://docs.python.org/3/tutorial/) or [brush up](https://www.w3schools.com/python/) at your convenience.
|
||||
|
||||
> While we do our best to assume no prior knowledge of Python, these are valuable topics of study for the aspiring OpenDBM users. Where sensible, we have linked to resources and articles that go more in depth.
|
||||
|
||||
## Developer Notes
|
||||
|
||||
People from many different development backgrounds are learning OpenDBM. You may have different experience between researchers, data scientist and python engineer and more. We try to write for all enthutiast from all backgrounds. Sometimes we provide explanations specific to one platform or another like so:
|
||||
|
||||
<Tabs groupId="guide" defaultValue="researchers" values={constants.getLibraryNotesTabs(["researchers","data_scientist","engineer"])}>
|
||||
|
||||
<TabItem value="researchers">
|
||||
|
||||
> Clinical Researchers may be familiar with this concept.
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="data_scientist">
|
||||
|
||||
> Data scientist may be familiar with this concept.
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="engineer">
|
||||
|
||||
> Python developers may be familiar with this concept.
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
---
|
||||
|
||||
Now that you know how this guide works, it's time to get to start OpenDBM installation: [Dependencies Installation](dependencies-installation.md).
|
||||
21
docs/docs/jitter.md
Normal file
21
docs/docs/jitter.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
id: jitter
|
||||
title: Jitter
|
||||
---
|
||||
|
||||
The jitter of an audio signal is the parameter of frequency variation from cycle to cycle[^1], and is affected mainly by the lack of control over vocal cord vibration.
|
||||
|
||||
[^1]: https://en.wikipedia.org/wiki/Jitter
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_jitter` | **Jitter.** Frame-wise measurements of jitter. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_jitter_mean` | **Jitter mean.** Mean of `aco_jitter` across the audio file. |
|
||||
| `aco_jitter_std` | **Jitter standard deviation.** Standard deviation of `aco_jitter` across the audio file. |
|
||||
14
docs/docs/lexical-richness.md
Normal file
14
docs/docs/lexical-richness.md
Normal file
@@ -0,0 +1,14 @@
|
||||
---
|
||||
id: lexical-richness
|
||||
title: Lexical Richness
|
||||
---
|
||||
|
||||
There are several terms for this measurement used across literature (sometimes also called diversity in vocabulary, etc.) and certainly more than one way to quantify it. We felt that an appropriate measure of richness of vocabulary would be the Moving Average Type Token Ratio (MATTR), reported in this paper by Convington and McFall[^1]. Simply put, it quantifies how many unique words are used in speech, which can be a proxy to some clinical measurements.
|
||||
|
||||
[^1]: Covington, M. A., & McFall, J. D. (2010). Cutting the Gordian knot: The moving-average type–token ratio (MATTR). *Journal of quantitative linguistics*, 17(2), 94-100.
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `nlp_mattr_mean` | **Lexical richness**, measured using the moving average type token ratio (MATTR). |
|
||||
100
docs/docs/mac-linux-usage.md
Normal file
100
docs/docs/mac-linux-usage.md
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
id: opendbm-docker-usage
|
||||
title: Mac / Linux Usage
|
||||
---
|
||||
|
||||
## Mac / Linux
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
Congratulations, it’s way easier to use OpenDBM on Mac or Linux compared to Windows.
|
||||
|
||||
Essentially, all you need to do is run a single command from the **open_dbm** folder. Here it is:
|
||||
|
||||
```bash
|
||||
% bash process_dbm.sh --input_path=<...> --output_path=<...>
|
||||
```
|
||||
|
||||
`bash` is the command that calls the script process_dbm.sh.
|
||||
|
||||
There are two required parameters, the `--input_path` and the `--output_path`. We’ll go over these in Sections 3.1.1 and 3.1.2. There are also two useful optional parameters: `--dbm_group` and `--tr`. We’ll go over those in Sections 3.1.3 and 3.1.4.
|
||||
|
||||
### Input path
|
||||
|
||||
This is simply the path to the data you want to process. For example, let’s pretend you want to process all the videos in the **sample_data** folder that comes included with OpenDBM:
|
||||
|
||||
<figure>
|
||||
<img src="/docs/assets/mac_linux_1.png" width="1000" alt="Sample Data screenshot" />
|
||||
<figcaption>Sample Data screenshot</figcaption>
|
||||
</figure>
|
||||
|
||||
The path to this data would be something like **/Users/JohnWick/open_dbm/sample_data**. So, for the `--input_path` parameter in the command, you’d put in the path to that folder like this: `--input_path=/Users/JohnWick/open_dbm/sample_data`. By doing so, you’re asking to process all four videos in that folder.
|
||||
> **Helpful tip:** On Mac, if you ‘copy’ the folder you want to process from **Finder** and ‘paste’ it into **Terminal**, it automatically pastes the path to that folder.
|
||||
|
||||
OpenDBM allows for processing of individual video/audio files or bulk processing of several video/audio files saved together in a folder. The input path can either lead to a single file, in which case only that file will be processed, or it can lead to a folder with several files, in which case all compatible files in that folder will be processed. This path can be anywhere.
|
||||
|
||||
All video files must be in **MP4** or **MOV** format and all audio files must be in **WAV** or **MP3** format. The current version of the package leaves the responsibility of converting file types to the correct format to the user; hopefully future versions will handle more file types. Please be careful when using online tools to convert video that may contain sensitive information. If the specified input path does not direct to any **MP4, MOV, WAV, or MP3** files, nothing will happen.
|
||||
|
||||
At this point, this is what our (incomplete) command would look like:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data
|
||||
--output_path=<...>
|
||||
```
|
||||
Just in case it’s causing any confusion to beginners, `--input_path` does not need to be on a new line here; I’m just showing it this way for clarity (you should enter everything on the same line). This applies to the whole document.
|
||||
|
||||
### Output Path
|
||||
|
||||
This is the path where a new folder named **output** will be created and all calculated digital biomarker data will be stored. The structure of the data output is described in Chapter 4.
|
||||
|
||||
Let’s say, in our example, we want to save our outputted variables on the **Desktop**. The processing command starts looking like this:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
```
|
||||
`--input_path` and `--output_path` are the only two mandatory parameters of the processing function. You should be able to process data at this point. The next two sections go over two optional inputs that are probably pretty good to be familiar with.
|
||||
|
||||
### DBM Group
|
||||
|
||||
There are several categories of digital biomarkers (DBMs) that are calculated by OpenDBM:
|
||||
|
||||
- **Facial,** referring to measurements of facial behavior
|
||||
- **Acoustic** , referring to measurements of vocal acoustics
|
||||
- **Speech,** referring to measurement of language characteristics
|
||||
- **Movement** , referring to motor and oculomotor functioning
|
||||
|
||||
By default, OpenDBM calculates all of these from any video that is inputted. If only audio is inputted, it calculates acoustic and speech variables. But the user may not be interested in all four types of variables (e.g., maybe they just want to calculate digital biomarkers related to vocal acoustics). In that case, the --dbm_group input can be used to limit the calculation to only that category of biomarker. This functionality exists both to reduce on processing time and to allow for simplicity during subsequent data analysis downstream (see Chapter 4).
|
||||
|
||||
There are four possible inputs here: facial, acoustic, speech, and movement.
|
||||
|
||||
So, if the user only wants acoustic biomarkers, the processing script would look like this:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
--dbm_group=’acoustic’
|
||||
```
|
||||
> **Note:** You do need to include the quotation marks around your input for --dbm_group.
|
||||
|
||||
If you want, you can also select more than one group of biomarkers. For example, if you wanted to calculate both acoustic and speech biomarkers but not facial or movement ones, your command would look like this:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
--dbm_group=’acoustic speech’
|
||||
```
|
||||
|
||||
### Transcription
|
||||
|
||||
If the data being processed contains speech, OpenDBM will transcribe that speech into text and calculate a number of measurements from the transcribed text (see Section 5.3 for all speech biomarker variables). However, the speech transcription itself is not saved. This is because it may not always be in the interest of the user to save the transcribed speech. In cases where the user is processing sensitive patient data that may contain [Protected Health Information (PHI)](https://www.hhs.gov/answers/hipaa/what-is-phi/index.html), **the transcribed speech is still considered PHI** and is subject to strict privacy regulations. Everything that is by default saved in the **output** folder is intentionally designed to not be PHI.
|
||||
|
||||
Now, if the user *wants* the transcribed text, they have the *option* to save it in the **output** folder. They can do this using the `--tr` parameter, and setting it to ‘on’, as shown below. When they do this, the transcribed text is saved in the output folder as described in Section 4.2.2.
|
||||
|
||||
We only advise that the user do this if the data output is being stored in a location where PHI data can be stored, and that the data output folder will never find its way to a place where PHI data can not be stored. I am not your lawyer, nor am I liable for the wrath of HIPAA and GDPR coming down upon you, but please know that transcribed speech is indeed considered PHI, and you do need to make sure you are following all regulations and have full patient consent for it.
|
||||
|
||||
```bash
|
||||
% bash process_dbm.sh --input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
--dbm_group=’acoustic speech’
|
||||
--tr=on
|
||||
```
|
||||
> **Note:** The ‘on’ in the `--tr` parameter does not require quotation marks. Why? VJ was lazy.
|
||||
|
||||
And that’s it! By executing the `bash process_dbm.sh` command as described in this chapter, you can process data and calculate digital biomarkers. Section 3.2 repeats all this information for folks on Windows. You can skip to Chapter 4, which details how the data output is structured.
|
||||
43
docs/docs/more-resources.md
Normal file
43
docs/docs/more-resources.md
Normal file
@@ -0,0 +1,43 @@
|
||||
---
|
||||
id: more-resources
|
||||
title: More Resources
|
||||
---
|
||||
|
||||
There’s always more to learn: how to use OpenDBM, OpenDBM Biomaker variables, Data Guidelines, and Resource
|
||||
|
||||
## Where to go from here
|
||||
|
||||
- [How to use OpenDBM](opendbm-docker-usage)
|
||||
- [Learn about OpenDBM output](opendbm-docker-output)
|
||||
- [OpenDBM Richful Biomaker Variables](biomaker-variables)
|
||||
- [OpenDBM Data Guidelines](data-guidelines)
|
||||
- [Learn about OpenDBM surrounding components](/extras/extras)
|
||||
- [Get involved in the OpenDBM community](/contributing/overview)
|
||||
|
||||
## Helpful Videos
|
||||
|
||||
Along with the initial launch of OpenDBM (v1.0), we released a set of instructional videos as well as a recording of the training webinar we conducted. We want to add to how many of these we have, but below is the current list of videos that are helpful in getting started with OpenDBM.
|
||||
|
||||
### OpenDBM Installation on Mac
|
||||
|
||||
[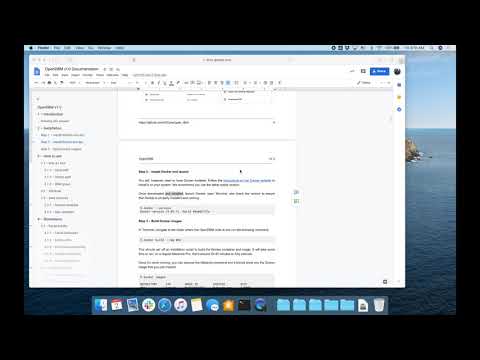](https://www.youtube.com/watch?v=CfNFBcf41u0)
|
||||
|
||||
This video walks through the installation as described in Chapter 2; please note that this was made during OpenDBM v1.0 so there may be small differences but it remains a helpful visual guide.
|
||||
|
||||
### OpenDBM How to Use on Mac
|
||||
|
||||
[](https://www.youtube.com/watch?v=TKON5UcxrwQ)
|
||||
|
||||
This video uses just the required parameters in the processing script to extract digital biomarker variables from the sample videos that are included with OpenDBM and is helpful to anyone getting started.
|
||||
|
||||
### OpenDBM Sample Analysis
|
||||
|
||||
[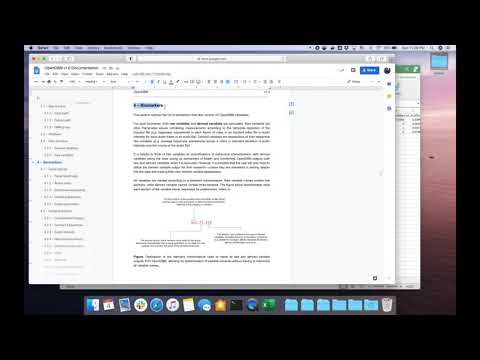](https://www.youtube.com/watch?v=QQY_QA1Y5BM)
|
||||
|
||||
This video uses the data output acquired in the previous video to conduct a made up experiment to analyze some of the digital biomarker data in order to test a hypothesis.
|
||||
|
||||
### OpenDBM Virtual Training Oct 5 2020
|
||||
|
||||
[](https://www.youtube.com/watch?v=PNS-TQX5CFc)
|
||||
|
||||
This is the recording of one of the webinars that were held for the initial launch of OpenDBM v1.0 in October of 2020. It has an overview of the philosophy behind OpenDBM as well as helpful instructions.
|
||||
43
docs/docs/opendbm-docker-output.md
Normal file
43
docs/docs/opendbm-docker-output.md
Normal file
@@ -0,0 +1,43 @@
|
||||
---
|
||||
id: opendbm-docker-output
|
||||
title: Docker Output
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
## OpenDBM Output
|
||||
|
||||
In the previous chapter, we went over how to process data using OpenDBM and learned that when we do so, we save a folder called **output** in the location we specify. This chapter is all about what’s in that folder and all the wonderful things we can do with it.
|
||||
|
||||
The first thing you’ll see is that the **output** folder is divided into `raw_variables` and `derived_variables`. As Chapter 5 explains, for each biomarker, both **raw variables** and **derived variables** are calculated. Raw variables are often frame-wise values containing measurements according to the temporal resolution of the inputted file (e.g. happiness expressivity in each frame of video in an inputted video file or audio intensity for each audio frame in an audio file). Derived variables are abstractions of their respective raw variables (e.g. average happiness expressivity across a video or standard deviation of audio intensity over the course of the audio file). Chapter 5 goes into more detail and lists all raw and derived biomarker variables. The purpose of this chapter is to first just explain the structure of the data output from OpenDBM.
|
||||
|
||||
## Derived Variables
|
||||
|
||||
For derived variables, a single CSV file is outputted. This CSV file, named derived_output.csv, contains a row for each video/audio file that was inputted. If only a single file was processed, the CSV file will have only one row. If several were inputted, then several rows will be outputted.
|
||||
|
||||
And, in case you forgot what files and/or excel sheets look like, here are some illustrations:
|
||||
<figure>
|
||||
<img src="../docs/assets/derived_var_1.png" width="1000" alt="Screenshot of output file" />
|
||||
<figcaption>Screenshot of output file.</figcaption>
|
||||
</figure>
|
||||
|
||||
Essentially, the derived variables CSV file is the best place to go for most simple analyses. [In this instructional video](https://www.youtube.com/watch?v=QQY_QA1Y5BM), we conduct a sample data analysis in a made-up experiment and use the derived variable output to test effects of a ‘treatment’ on emotional expressivity in the face.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
The raw variable data structure is slightly more complicated. The hierarchy is described below:
|
||||
<figure>
|
||||
<img src="../docs/assets/raw_variables1.png" width="1000" alt="Variables hierarchy" />
|
||||
<figcaption>Variables hierarchy</figcaption>
|
||||
</figure>
|
||||
|
||||
Under the **raw_variables** folder, there will be a folder for each **filename**. Under each filename’s folder, there will be a folder for each DBM group as described in Section 3.1.3 and Chapter 5: **facial, acoustic, speech, and movement**. In each of the DBM group folders, there will be sub- folders for biomarkers e.g. the acoustic **intensity** folder has data for audio intensity (Section 5.2.3). WIthin the biomarker folder will be a CSV file that contains frame-by-frame values for variables in it. In the case of audio intensity, the audio intensity raw variable CSV file has the `aco_int` values in decibels for *each frame of audio* in the video file, whereas the `aco_int_mean` *derived* variable would simply have the mean intensity of all frames in that file.
|
||||
|
||||
### OpenFace output
|
||||
|
||||
As has been mentioned before, OpenDBM relies on OpenFace for a lot of its measurements. In case the user is interested in going upstream to that level of data, the **<filename\>_openface** folder just contains the OpenFace output, including action units, eye gaze data, and head movement calculations. Some other facial and movement measurements are acquired using facial landmark data, which is also an output from OpenFace, though relies on a different model. That OpenFace data is saved in **<filename\>_openface_lmk**. Both of the raw OpenFace output folders are there in case a user is interested in building their own raw / derived variables. If the user is simply interested in using OpenDBM’s existing measures, they can ignore these folders.
|
||||
|
||||
### Speech transcription
|
||||
|
||||
|
||||
Assuming the user used the `--tr=on` option when executing the processing command, OpenDBM will save the text for any speech that was transcribed in a folder called **deepspeech**. All transcription is done using an open source software package called [DeepSpeech](https://github.com/mozilla/DeepSpeech) This folder simply contains the output that DeepSpeech provides. Similar to the OpenFace output, the speech transcription is saved in case the user wants to dig deeper and perhaps derive their own measures. We do ask that you read Section 3.1.4 before you save speech transcriptions.
|
||||
100
docs/docs/opendbm-docker-usage.md
Normal file
100
docs/docs/opendbm-docker-usage.md
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
id: opendbm-docker-usage
|
||||
title: Docker Usage
|
||||
---
|
||||
|
||||
## Mac / Linux
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
Congratulations, it’s way easier to use OpenDBM on Mac or Linux compared to Windows.
|
||||
|
||||
Essentially, all you need to do is run a single command from the **open_dbm** folder. Here it is:
|
||||
|
||||
```bash
|
||||
% bash process_dbm.sh --input_path=<...> --output_path=<...>
|
||||
```
|
||||
|
||||
`bash` is the command that calls the script process_dbm.sh.
|
||||
|
||||
There are two required parameters, the `--input_path` and the `--output_path`. We’ll go over these in Sections 3.1.1 and 3.1.2. There are also two useful optional parameters: `--dbm_group` and `--tr`. We’ll go over those in Sections 3.1.3 and 3.1.4.
|
||||
|
||||
### Input path
|
||||
|
||||
This is simply the path to the data you want to process. For example, let’s pretend you want to process all the videos in the **sample_data** folder that comes included with OpenDBM:
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/mac_linux_1.png" width="1000" alt="Sample Data screenshot" />
|
||||
<figcaption>Sample Data screenshot</figcaption>
|
||||
</figure>
|
||||
|
||||
The path to this data would be something like **/Users/JohnWick/open_dbm/sample_data**. So, for the `--input_path` parameter in the command, you’d put in the path to that folder like this: `--input_path=/Users/JohnWick/open_dbm/sample_data`. By doing so, you’re asking to process all four videos in that folder.
|
||||
> **Helpful tip:** On Mac, if you ‘copy’ the folder you want to process from **Finder** and ‘paste’ it into **Terminal**, it automatically pastes the path to that folder.
|
||||
|
||||
OpenDBM allows for processing of individual video/audio files or bulk processing of several video/audio files saved together in a folder. The input path can either lead to a single file, in which case only that file will be processed, or it can lead to a folder with several files, in which case all compatible files in that folder will be processed. This path can be anywhere.
|
||||
|
||||
All video files must be in **MP4** or **MOV** format and all audio files must be in **WAV** or **MP3** format. The current version of the package leaves the responsibility of converting file types to the correct format to the user; hopefully future versions will handle more file types. Please be careful when using online tools to convert video that may contain sensitive information. If the specified input path does not direct to any **MP4, MOV, WAV, or MP3** files, nothing will happen.
|
||||
|
||||
At this point, this is what our (incomplete) command would look like:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data
|
||||
--output_path=<...>
|
||||
```
|
||||
Just in case it’s causing any confusion to beginners, `--input_path` does not need to be on a new line here; I’m just showing it this way for clarity (you should enter everything on the same line). This applies to the whole document.
|
||||
|
||||
### Output Path
|
||||
|
||||
This is the path where a new folder named **output** will be created and all calculated digital biomarker data will be stored. The structure of the data output is described in Chapter 4.
|
||||
|
||||
Let’s say, in our example, we want to save our outputted variables on the **Desktop**. The processing command starts looking like this:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
```
|
||||
`--input_path` and `--output_path` are the only two mandatory parameters of the processing function. You should be able to process data at this point. The next two sections go over two optional inputs that are probably pretty good to be familiar with.
|
||||
|
||||
### DBM Group
|
||||
|
||||
There are several categories of digital biomarkers (DBMs) that are calculated by OpenDBM:
|
||||
|
||||
- **Facial,** referring to measurements of facial behavior
|
||||
- **Acoustic** , referring to measurements of vocal acoustics
|
||||
- **Speech,** referring to measurement of language characteristics
|
||||
- **Movement** , referring to motor and oculomotor functioning
|
||||
|
||||
By default, OpenDBM calculates all of these from any video that is inputted. If only audio is inputted, it calculates acoustic and speech variables. But the user may not be interested in all four types of variables (e.g., maybe they just want to calculate digital biomarkers related to vocal acoustics). In that case, the --dbm_group input can be used to limit the calculation to only that category of biomarker. This functionality exists both to reduce on processing time and to allow for simplicity during subsequent data analysis downstream (see Chapter 4).
|
||||
|
||||
There are four possible inputs here: facial, acoustic, speech, and movement.
|
||||
|
||||
So, if the user only wants acoustic biomarkers, the processing script would look like this:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
--dbm_group=’acoustic’
|
||||
```
|
||||
> **Note:** You do need to include the quotation marks around your input for --dbm_group.
|
||||
|
||||
If you want, you can also select more than one group of biomarkers. For example, if you wanted to calculate both acoustic and speech biomarkers but not facial or movement ones, your command would look like this:
|
||||
```bash
|
||||
% bash process_dbm.sh
|
||||
--input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
--dbm_group=’acoustic speech’
|
||||
```
|
||||
|
||||
### Transcription
|
||||
|
||||
If the data being processed contains speech, OpenDBM will transcribe that speech into text and calculate a number of measurements from the transcribed text (see Section 5.3 for all speech biomarker variables). However, the speech transcription itself is not saved. This is because it may not always be in the interest of the user to save the transcribed speech. In cases where the user is processing sensitive patient data that may contain [Protected Health Information (PHI)](https://www.hhs.gov/answers/hipaa/what-is-phi/index.html), **the transcribed speech is still considered PHI** and is subject to strict privacy regulations. Everything that is by default saved in the **output** folder is intentionally designed to not be PHI.
|
||||
|
||||
Now, if the user *wants* the transcribed text, they have the *option* to save it in the **output** folder. They can do this using the `--tr` parameter, and setting it to ‘on’, as shown below. When they do this, the transcribed text is saved in the output folder as described in Section 4.2.2.
|
||||
|
||||
We only advise that the user do this if the data output is being stored in a location where PHI data can be stored, and that the data output folder will never find its way to a place where PHI data can not be stored. I am not your lawyer, nor am I liable for the wrath of HIPAA and GDPR coming down upon you, but please know that transcribed speech is indeed considered PHI, and you do need to make sure you are following all regulations and have full patient consent for it.
|
||||
|
||||
```bash
|
||||
% bash process_dbm.sh --input_path=/Users/JohnWick/open_dbm/sample_data --output_path=/Users/JohnWick/Desktop
|
||||
--dbm_group=’acoustic speech’
|
||||
--tr=on
|
||||
```
|
||||
> **Note:** The ‘on’ in the `--tr` parameter does not require quotation marks. Why? VJ was lazy.
|
||||
|
||||
And that’s it! By executing the `bash process_dbm.sh` command as described in this chapter, you can process data and calculate digital biomarkers. Section 3.2 repeats all this information for folks on Windows. You can skip to Chapter 4, which details how the data output is structured.
|
||||
96
docs/docs/openface-docker-installation.md
Normal file
96
docs/docs/openface-docker-installation.md
Normal file
@@ -0,0 +1,96 @@
|
||||
---
|
||||
id: openface-docker-installation
|
||||
title: OpenFace Installation
|
||||
description: 'OpenDBM needs you to install OpenFace Model before running OpenDBM Facial and Movement components'
|
||||
hide_table_of_contents: true
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
This page will help you install OpenFace model that is stored as Docker Image, starting from on how to install the docker.
|
||||
|
||||
|
||||
<Tabs groupId="guide" defaultValue={constants.defaultGuideDocker} values={constants.guidesDocker}>
|
||||
<TabItem value={constants.defaultGuideDocker}>
|
||||
|
||||
## If you have installed Docker
|
||||
|
||||
**NOTE**: Make sure to sign in first so you can download the docker image
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/docker-signin.png" width="30%" alt="OpenDBM Folder" />
|
||||
|
||||
</figure>
|
||||
|
||||
And then execute this command to download OpenFace model
|
||||
```bash
|
||||
docker pull opendbmteam/dbm-openface
|
||||
```
|
||||
Done!
|
||||
## If you haven't, here's the instruction on how to install Docker
|
||||
|
||||
|
||||
The instructions are a bit different depending on your development operating system.
|
||||
|
||||
#### Development OS
|
||||
|
||||
<Tabs groupId="os" defaultValue={constants.defaultOs} values={constants.oses} className="pill-tabs">
|
||||
<TabItem value="macos">
|
||||
|
||||
Follow the instruction in the [official website](https://docs.docker.com/desktop/install/mac-install/)
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="linux">
|
||||
|
||||
Follow the instruction in the [official website](https://docs.docker.com/desktop/install/linux-install/)
|
||||
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="windows">
|
||||
|
||||
1. Follow the instruction in the [official website](https://docs.docker.com/desktop/install/windows-install/)
|
||||
|
||||
**IMPORTANT NOTE**:
|
||||
* Please follow the instructions to install **WSL-2** as system requirements instead of Hyper-V. Because we relying on WSL command to execute OpenFace Model.
|
||||
* After you installed WSL in [Linux kernel update package](https://docs.microsoft.com/en-us/windows/wsl/install):
|
||||
* Make sure to execute "wsl --set-default-version 2"
|
||||
* Make sure to choose Ubuntu as Linux distribution of choice
|
||||
* **wsl -l -o** to list distribution
|
||||
* **wsl --install -d Ubuntu-18.04** to install Ubuntu Distribution
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/ubuntu-wsl.png" width="70%" alt="OpenDBM Folder" />
|
||||
<figcaption>Example on how to List Distribution and Install Ubuntu</figcaption>
|
||||
</figure>
|
||||
|
||||
2. After WSL and Docker is installed. check if Docker use WSL Integration by go to the Settings > Resources > WSL Integrations, and then enable Ubuntu as our Linux Distribution.
|
||||
<figure>
|
||||
<img src="../docs/assets/ubuntu-enable-docker.png" width="100%" alt="OpenDBM Folder" />
|
||||
<figcaption>WSL Integration in Docker Setting</figcaption>
|
||||
</figure>
|
||||
|
||||
|
||||
|
||||
3. Make sure check and set wsl distributions to Linux distributions of your choice. In powershell/command prompt:
|
||||
* Type **wsl --list** to check WSL distributions list
|
||||
* **wsl --setdefault {Distribution Name}** to set the default distribution **(Use Ubuntu)**
|
||||
* **wsl --list** again to check if wsl default is set
|
||||
|
||||
<figure>
|
||||
<img src="../docs/assets/ubuntu-set-dist.png" width="100%" alt="OpenDBM Folder" />
|
||||
<figcaption>Set Default WSL</figcaption>
|
||||
</figure>
|
||||
|
||||
|
||||
4. And it's done! Now you can go to the next step by pulling the docker image from the step [above](#top)
|
||||
|
||||
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
|
||||
|
||||
34
docs/docs/overall-expressivity.md
Normal file
34
docs/docs/overall-expressivity.md
Normal file
@@ -0,0 +1,34 @@
|
||||
---
|
||||
id: overall-expressivity
|
||||
title: Overall expressivity
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
|
||||
Overall expressivity is a measure of facial expressivity regardless of emotional state. All action unit values are combined to determine the overall expressivity of the face, typically useful for measurement of blunted affect or disruption of facial expression as a consequence of motor retardation.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_comintsoft` | **Overall expressivity ‘soft’,** equivalent to the average of all `fac_EMOintsoft` variables. |
|
||||
| `fac_cominthard` | **Overall expressivity ‘hard’,** equivalent to the average of all `fac_cominthard` variables. |
|
||||
| `fac_comlowintsoft` | **Overall expressivity ‘soft’,** for the lower half of the face. |
|
||||
| `fac_comlowinthard` | **Overall expressivity 'hard',** for the lower half of the face. |
|
||||
| `fac_comuppintsoft` | **Overall expressivity ‘soft’,** for the upper half of the face. |
|
||||
| `fac_comuppinthard` | **Overall expressivity hard,** for the upper half of the face. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_comintsoft_pct` | **Overall expressivity as measured through presence of emotions** i.e. the number of frames when any given emotion was being detected. |
|
||||
| `fac_comintsoft_mean` | **Overall expressivity ‘soft’ mean,** equal to the average of all `fac_comintsoft` values. |
|
||||
| `fac_comintsoft_std` | **Overall expressivity ‘soft’ standard deviation,** i.e. the standard deviation of `fac_comintsoft`. |
|
||||
| `fac_cominthard_mean` | **Overall expressivity ‘hard’ mean,** equal to the average of all fac_cominthard values. |
|
||||
| `fac_cominthard_std` | **Overall expressivity ‘hard’ standard deviation,** i.e. the standard deviation of `fac_comintsoft`. |
|
||||
| `fac_comlowintsoft_pct` | Percentage of frames where any given emotion was detected in the lower half of the face. |
|
||||
| `fac_comlowintsoft_mean` | **Overall expressivity ‘soft’ mean,** for the lower half of the face. |
|
||||
| `fac_comlowintsoft_std` | **Overall expressivity ‘soft’ standard deviation,** for the lower half of the face. |
|
||||
| `fac_comuppinthard_mean` | **Overall expressivity ‘hard’ mean,** for the upper half of the face. |
|
||||
| `fac_comuppinthard_std` | **Overall expressivity ‘hard’ standard deviation,** for the upper half of the face. |
|
||||
26
docs/docs/pain-expressivity.md
Normal file
26
docs/docs/pain-expressivity.md
Normal file
@@ -0,0 +1,26 @@
|
||||
---
|
||||
id: pain-expressivity
|
||||
title: Pain Expressivity
|
||||
---
|
||||
|
||||
Similar to emotion expressivity, pain expressivity is calculated using a combination of action units as defined in the Facial Action Coding System (FACS)[^1]. The following action units have been found to be associated with pain according to reports in the scientific literature: 4 + 6 + 7 + 9 + 10 + 12 + 20 + 26.[^2]
|
||||
|
||||
[^1]: https://en.wikipedia.org/wiki/Facial_Action_Coding_System
|
||||
[^2]: Prkachin, Kenneth M. (1992). The consistency of facial expressions of pain: a comparison across modalities. Pain, 51(3), 297–306.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_paiintsoft` | **Pain intensity ‘soft’.** Continuous vector indicating intensity of pain in each video frame regardless of whether *all* action units for that emotion are present. Range is between 0 and 1. |
|
||||
| `fac_paiinthard` | **Pain intensity ‘hard’.** Continuous vector indicating intensity of pain in each video frame, only providing non-zero value if *all* action units for that emotion are present. Range is between 0 and 1. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `fac_paiintsoft_pct` | Percentage of frames where at least one of the pain AUs were detected. |
|
||||
| `fac_paiintsoft_mean` | **Pain expressivity ‘soft’ mean,** equal to the average of all `fac_paiintsoft` values. |
|
||||
| `fac_paiintsoft_std` | **Pain expressivity ‘soft’ standard deviation.** |
|
||||
| `fac_paiinthard_mean` | **Pain expressivity ‘hard’ mean,** equal to the average of all fac_paiinthard values. |
|
||||
| `fac_paiinthard_std` | **Pain expressivity ‘hard’ standard deviation.** |
|
||||
24
docs/docs/parts-of-speech.md
Normal file
24
docs/docs/parts-of-speech.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
id: parts-of-speech
|
||||
title: Parts of Speech
|
||||
---
|
||||
|
||||
Parts of speech simply describe aspects of the language used, such as usage of verbs, pronouns, adjectives, etc. along with other helpful measures such as the number of sentences spoken. These are acquired through NLTK.
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `nlp_numSentences_mean` | **Number of sentences** detected over the course of the video. |
|
||||
| `nlp_singPronPerAns_mean` | **Number of singular pronouns** detected over the course of the video. |
|
||||
| `nlp_singPronPerSen_mean` | **Number of singular pronouns per sentence** detected over the course of the video. |
|
||||
| `nlp_pastTensePerAns_mean` | **Number of words spoken in past tense** detected over the course of the video. |
|
||||
| `nlp_pastTensePerSen_mean` | **Number of words spoken in past tense per sentence** detected over the course of the video. |
|
||||
| `nlp_pronounsPerAns_mean` | **Number of pronouns used** detected over the course of the video. |
|
||||
| `nlp_pronounsPerSen_mean` | **Number of pronouns used per sentence** detected over the course of the video. |
|
||||
| `nlp_verbsPerAns_mean` | **Number of verbs used** detected over the course of the video. |
|
||||
| `nlp_verbsPerSen_mean` | **Number of verbs used per sentence** detected over the course of the video. |
|
||||
| `nlp_adjectivesPerAns_mean` | **Number of adjectives used** detected over the course of the video. |
|
||||
| `nlp_adjectivesPerSen_mean` | **Number of adjectives used per sentence** detected over the course of the video. |
|
||||
| `nlp_nounsPerAns_mean` | **Number of nouns used** detected over the course of the video. |
|
||||
| `nlp_nounsPerSen_mean` | **Number of nouns used per sentence** detected over the course of the video. |
|
||||
28
docs/docs/pause-characteristics.md
Normal file
28
docs/docs/pause-characteristics.md
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
id: pause-characteristics
|
||||
title: Pause Characteristics
|
||||
---
|
||||
|
||||
Fundamental frequency is usually zero when there is no voice detected. Using this understanding, frames where voice is or is not present can be determined and used to characterize pauses during speech and silence during the audio file. These metrics are quantified here.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_pausetime` | **Pause time.** Length of time with no speech detected. |
|
||||
| `aco_totaltime` | **Video length.** The length of the video. |
|
||||
| `aco_speakingtime` | **Time spoken.** The total length of time with speech detected. |
|
||||
| `aco_numpauses` | **Number of pauses.** Number of instances with no speech. |
|
||||
| `aco_pausefrac` | **Pause time.** aco_pausetime divided by aco_totaltime. |
|
||||
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_pausetime_mean` | **Pause time.** Length of time with no speech detected. |
|
||||
| `aco_totaltime_mean` | **Video length.** The length of the video. |
|
||||
| `aco_numpauses_mean` | **Number of pauses.** Number of instances with no speech. |
|
||||
| `aco_pausefrac_mean` | **Fraction of video with pauses.** `aco_pausetime_mean` divided by `aco_totaltime_mean`. |
|
||||
|
||||
> Note: The overlap between raw and derived variables for this section may be confusing; it’s a leftover effect of how our code is organized in the AiCure product, where several videos from the same individual at the same time point are averaged. For your purposes, simply rely on the derived variables here.
|
||||
20
docs/docs/pro-installation.md
Normal file
20
docs/docs/pro-installation.md
Normal file
@@ -0,0 +1,20 @@
|
||||
---
|
||||
id: pro-installation
|
||||
title: Installation for Pro
|
||||
description: Pro Installation
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem'; import constants from '@site/core/TabsConstants';
|
||||
import ThemedImage from '@theme/ThemedImage';
|
||||
|
||||
**NOTE for Windows User**: Please use the instruction [here](openface-docker-installation#if-you-havent-heres-the-instruction-on-how-to-install-docker) to install docker and/or enable WSL 2 as Docker Integration
|
||||
|
||||
Clone OpenDBM onto your system. Make sure you have docker installed and running. From the repo, run
|
||||
```bash
|
||||
docker build --tag dbm .
|
||||
```
|
||||
to install the docker image. Then, you’re good to go.
|
||||
|
||||
---
|
||||
|
||||
Now that you’ve covered OpenDBM installation, let’s dive deeper on some of these core modules by looking at [Usage](opendbm-docker-usage).
|
||||
15
docs/docs/rate-of-speech.md
Normal file
15
docs/docs/rate-of-speech.md
Normal file
@@ -0,0 +1,15 @@
|
||||
---
|
||||
id: rate-of-speech
|
||||
title: Rate of Speech
|
||||
---
|
||||
|
||||
Rate of speech is simply a measure of words spoken per given unit of time. We measure this in words spoken per minute. However, for convenience, we are also outputting as a variable simply the length of the file that was analyzed and hence multiplying `nlp_wordsPerMin_mean` by `nlp_totalTime_mean` will give the total number of words spoken.
|
||||
|
||||
> Please note that the latter measurement is in seconds, so one would have to divide it by 60 first :)
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `nlp_wordsPerMin_mean` | **Rate of speech**, in average number of words spoken per minute. |
|
||||
| `nlp_totalTime_mean` | **Total time in seconds**, of the video or audio file from which the rate of speech measurement was acquired. |
|
||||
22
docs/docs/raw-variables.md
Normal file
22
docs/docs/raw-variables.md
Normal file
@@ -0,0 +1,22 @@
|
||||
---
|
||||
id: raw-variables
|
||||
title: Raw Variables
|
||||
---
|
||||
|
||||
## Raw Variables
|
||||
|
||||
The raw variable data structure is slightly more complicated. The hierarchy is described below:
|
||||
<figure>
|
||||
<img src="../docs/assets/raw_variables1.png" width="1000" alt="Variables hierarchy" />
|
||||
<figcaption>Variables hierarchy</figcaption>
|
||||
</figure>
|
||||
|
||||
Under the **raw_variables** folder, there will be a folder for each **filename**. Under each filename’s folder, there will be a folder for each DBM group as described in Section 3.1.3 and Chapter 5: **facial, acoustic, speech, and movement**. In each of the DBM group folders, there will be sub- folders for biomarkers e.g. the acoustic **intensity** folder has data for audio intensity (Section 5.2.3). WIthin the biomarker folder will be a CSV file that contains frame-by-frame values for variables in it. In the case of audio intensity, the audio intensity raw variable CSV file has the `aco_int` values in decibels for *each frame of audio* in the video file, whereas the `aco_int_mean` *derived* variable would simply have the mean intensity of all frames in that file.
|
||||
|
||||
### OpenFace output
|
||||
|
||||
As has been mentioned before, OpenDBM relies on OpenFace for a lot of its measurements. In case the user is interested in going upstream to that level of data, the **<filename\>_openface** folder just contains the OpenFace output, including action units, eye gaze data, and head movement calculations. Some other facial and movement measurements are acquired using facial landmark data, which is also an output from OpenFace, though relies on a different model. That OpenFace data is saved in **<filename\>_openface_lmk**. Both of the raw OpenFace output folders are there in case a user is interested in building their own raw / derived variables. If the user is simply interested in using OpenDBM’s existing measures, they can ignore these folders.
|
||||
|
||||
### Speech transcription
|
||||
|
||||
Assuming the user used the `--tr=on` option when executing the processing command, OpenDBM will save the text for any speech that was transcribed in a folder called **deepspeech**. All transcription is done using an open source software package called [DeepSpeech](https://github.com/mozilla/DeepSpeech) This folder simply contains the output that DeepSpeech provides. Similar to the OpenFace output, the speech transcription is saved in case the user wants to dig deeper and perhaps derive their own measures. We do ask that you read Section 3.1.4 before you save speech transcriptions.
|
||||
12
docs/docs/sentiment-of-speech.md
Normal file
12
docs/docs/sentiment-of-speech.md
Normal file
@@ -0,0 +1,12 @@
|
||||
---
|
||||
id: sentiment-of-speech
|
||||
title: Sentiment of Speech
|
||||
---
|
||||
|
||||
This refers to the emotional valence of the transcribed text based. This determination is based on pre-trained models found in the [vaderSentiment](https://pypi.org/project/vaderSentiment/ ) library. Positive values of sentiment indicate positive emotional valence, while negative values indicate negative emotional valence.
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `nlp_sentiment_mean_mean` | **Sentiment of speech**, ranging from -1 to 1, with -1 indicative negatively valenced speech and +1 indicative positively valenced speech. |
|
||||
21
docs/docs/shimmer.md
Normal file
21
docs/docs/shimmer.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
id: shimmer
|
||||
title: Shimmer
|
||||
---
|
||||
|
||||
The shimmer of an audio signal is the cycle-to-cycle amplitude variation of the sound wave.[^1]
|
||||
|
||||
[^1]: Horii, Y. (1980). Vocal shimmer in sustained phonation. Journal of Speech, Language, and Hearing Research, 23(1), 202-209.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_shimmer` | **Shimmer.** Frame-wise measurements of shimmer. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_shimmer_mean` | **Shimmer mean.** Mean of `aco_shimmer` across the audio file. |
|
||||
| `aco_shimmer_std` | **Shimmer standard deviation.** Standard deviation of `aco_shimmer` across the audio file. |
|
||||
8
docs/docs/speech.md
Normal file
8
docs/docs/speech.md
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
id: speech
|
||||
title: Speech
|
||||
---
|
||||
|
||||
The previous section focused on acoustic properties of speech. This section measures characteristics of language. First, any speech detected in the audio file is transcribed into text using [DeepSpeech](https://github.com/mozilla/DeepSpeech), an open-source speech transcription tool. From the transcribed text, a number of open source natural language processing tools are used to derive characteristics of speech.
|
||||
|
||||
Speech biomarkers are slightly different from the other categories of digital biomarkers as the ‘raw variables’ are really just the transcribed speech (on how to acquire the transcribed speech, see Section 3.1.4). For reasons that are unimportant, we do still calculate raw variables and derived variables separately here, but there is absolutely no difference between the raw and derived variables. Hence, we recommend conducting any analysis on speech data simply from the derived variables, listed below.
|
||||
6
docs/docs/supported-file-types.md
Normal file
6
docs/docs/supported-file-types.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
id: supported-file-types
|
||||
title: Supported File Types
|
||||
---
|
||||
|
||||
First and foremost––OpenDBM only supports MP4 and MOV for video files and MP3 and WAV for audio files. Though there are several freely available online tools to convert file types quickly and easily, we advise that you be careful when using them given they do not guarantee data privacy and security. Instead, there are python packages available for local file conversion. Future versions of OpenDBM may support additional file types. For now, the user is responsible for doing this.
|
||||
10
docs/docs/tutorial.md
Normal file
10
docs/docs/tutorial.md
Normal file
@@ -0,0 +1,10 @@
|
||||
---
|
||||
id: tutorial
|
||||
title: Learn the Basics
|
||||
---
|
||||
|
||||
Tutorial template
|
||||
|
||||
## Hello World
|
||||
|
||||
Template hello world
|
||||
14
docs/docs/verbal-acoustic.md
Normal file
14
docs/docs/verbal-acoustic.md
Normal file
@@ -0,0 +1,14 @@
|
||||
---
|
||||
id: verbal-acoustic
|
||||
title: Verbal Acoustic
|
||||
---
|
||||
|
||||
Verbal acoustics refer to measurements of the acoustic properties of an individual’s voice.
|
||||
|
||||
It is important to note that OpenDBM does not yet filter out noise from voice. Hence, verbal acoustic variables are measurements of all audio that is inputted. Hence, inputted audio files must not have too much noise in order to obtain a high signal-to-noise ratio in the measurements.
|
||||
|
||||
All verbal acoustic variables outlined here are acquired through use of Parselmouth[^1], which is a python implementation of the Praat software library[^2], a commonly used software tool for quantification of verbal acoustics. Raw variables are calculated for each audio frame (with exception of pause characteristics and voice prevalence) and derived variables abstract those measurements at the level of the audio file.
|
||||
|
||||
[^1]: https://pypi.org/project/praat-parselmouth/
|
||||
[^2]: http://www.fon.hum.uva.nl/praat/
|
||||
|
||||
20
docs/docs/video-guidelines.md
Normal file
20
docs/docs/video-guidelines.md
Normal file
@@ -0,0 +1,20 @@
|
||||
---
|
||||
id: video-guidelines
|
||||
title: Video Guidelines
|
||||
---
|
||||
|
||||
Generally speaking––and forgive me if this is too obvious––OpenDBM is meant to calculate behavioral characteristics and subsequently derive digital biomarkers from video of an individual’s head/face area and there is a basic expectation that the video will be of that individual (e.g. patient during a clinical interview) facing generally towards the direction of the camera lens. Some key points to consider regarding video that is processed are detailed below.
|
||||
|
||||
## Direction of head
|
||||
|
||||
If for some frames of the video, the head is not pointing towards the camera, it is possible that no visual biomarker variables will be processed for those frames. Hence, it is recommended that most if not all of the video be of the face pointing towards the camera. To find out which frames in a video were or were not processed, go through the raw variable output and locate any **nan** entries: those are likely because there was no face detected in those frames (there’s more on this in Section 5.1).
|
||||
|
||||
## Persons per video
|
||||
|
||||
Each video should be unique to one person. If more than one person is present in any given frame of video, the package will get confused and only make measurements on one of the heads/faces, with no real way to determine which one of the individuals is being used to make the measurements. Furthermore, even if one head is shown at a time but the same video contains more than one unique person, then the derived variable measurements will be disrupted in that they will be averaged for all faces shown, instead of limiting calculations to a unique face.
|
||||
|
||||
In many cases, the user may be processing videos of a clinician-patient interview and that video either contains shots of both the interviewer and the patient’s face (such as [this one](https://youtu.be/7_gmIvbjt3w?t=138)). The user must spatially crop the video to ensure that only the face of the individual whose behavior the user is interested in measuring (I’m assuming it’s the patient) is in the video––not the interviewer. In other cases, the video may cycle between the patient and interviewer (such as [this one](https://www.youtube.com/watch?v=4YhpWZCdiZc&t=302s)). Here, the user must temporally crop the video so that only shots that contain the patient’s face are processed, and not the ones of the interviewer’s face. It can also be the case that a caretaker or guardian is sitting next to the patient during the interview (such as [this one](https://youtu.be/I7QiPXqL9pY?t=117)). Here, too, the user must spatially crop the video to only include the face of the individual whose behavior they want to measure.
|
||||
|
||||
## Video data quality
|
||||
|
||||
Please be cognizant of data quality. This includes ensuring that the face is close enough to the camera that individual features are distinguishable, that lighting is consistent across the face e.g. there are no strong shadows, etc. that are going across the face, which could affect the calculations. It is also important that the entirety of the face is in the frame, which can sometimes be an issue if the face is too close to the camera e.g. if the individual is recording on a smartphone front-facing camera and brings it close to their face to speak.
|
||||
28
docs/docs/vocal-tremor.md
Normal file
28
docs/docs/vocal-tremor.md
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
id: vocal-tremor
|
||||
title: Vocal Tremor
|
||||
---
|
||||
|
||||
Vocal tremor is measured according to the methods described in [this paper](https://www.researchgate.net/publication/288142544_Vocal_tremor_measurement_based_on_autocorrelation_of_contours) by Marcus Bruckl and we highly suggest reading that work to help better understand the variables below.
|
||||
|
||||
### Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_freqtremfreq` | **Frequency tremor frequency (FTrF):** Frequency of the strongest low-frequency modulation of Fundamental frequency contour. |
|
||||
| `mov_freqtremindex` | **Frequency tremor intensity index (FTrI):** Intensity or magnitude of the strongest low frequency modulation of Fundamental frequency contour. |
|
||||
| `mov_freqtrempindex` | **Frequency tremor power index (FTrP):** Power index of the strongest low frequency modulation of Fundamental frequency contour. |
|
||||
| `mov_amptremfreq` | **Amplitude tremor frequency (ATrF):** Frequency of the strongest low-frequency modulation of Amplitude contour. |
|
||||
| `mov_amptremindex` | **Amplitude tremor intensity index (ATrI):** Intensity/magnitude of the strongest low frequency modulation of Amplitude contour. |
|
||||
| `mov_amptrempindex` | **Amplitude tremor power index (ATrP):** Power index of the strongest low frequency modulation of Amplitude contour. |
|
||||
|
||||
### Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `mov_freqtremfreq_mean` | **Mean frequency tremor frequency (FTrF):** Frequency of the strongest low-frequency modulation of Fundamental frequency contour. |
|
||||
| `mov_freqtremindex_mean` | **Mean frequency tremor intensity index (FTrI):** Intensity or magnitude of the strongest low frequency modulation of Fundamental frequency contour.contour. |
|
||||
| `mov_freqtrempindex_mean` | **Mean frequency tremor power index (FTrP):** Power index of the strongest low frequency modulation of Fundamental frequency contour. |
|
||||
| `mov_amptremfreq_mean` | **Mean amplitude tremor frequency (ATrF):** Frequency of the strongest low-frequency modulation of Amplitude contour. |
|
||||
| `mov_amptremindex_mean` | **Mean amplitude tremor intensity index (ATrI):** Intensity/magnitude of the strongest low frequency modulation of Amplitude contour. |
|
||||
| `mov_amptrempindex_mean` | **Mean amplitude tremor power index (ATrP):** Power index of the strongest low frequency modulation of Amplitude contour. |
|
||||
20
docs/docs/voice-prevalence.md
Normal file
20
docs/docs/voice-prevalence.md
Normal file
@@ -0,0 +1,20 @@
|
||||
---
|
||||
id: voice-prevalence
|
||||
title: Voice Prevalence
|
||||
---
|
||||
|
||||
Using knowledge on which audio frames do and do not contain voice, the prevalence of voice as opposed to silence across the audio file is also calculated simply as a derived variable.
|
||||
|
||||
## Raw Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_voiceframe` | **Voice frames.** Number of frames in the audio where speech was detected. |
|
||||
| `aco_totvoiceframe` | **Total frames.** Total number of frames in the audio. |
|
||||
| `aco_voicepct` | **Percentage of frames with voice.** `aco_voiceframe` divided by `aco_totvoiceframe`. |
|
||||
|
||||
## Derived Variables
|
||||
|
||||
| Variable | Description |
|
||||
| ----------- | ----------- |
|
||||
| `aco_voicepct_mean` | **Percentage of frames with voice mean.** |
|
||||
117
docs/docs/windows-usage.md
Normal file
117
docs/docs/windows-usage.md
Normal file
@@ -0,0 +1,117 @@
|
||||
---
|
||||
id: windows-usage
|
||||
title: Windows Usage
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem';
|
||||
|
||||
## Windows
|
||||
|
||||
Here, we will walk you through how to use the pipeline on Windows. Unfortunately, this process is a little more involved than on Mac/Linux.
|
||||
|
||||
### Starting the container
|
||||
|
||||
After a successful build (see Section 2), running the following command should show you something like this:
|
||||
```bash
|
||||
> docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
dbm latest 91e593533c96 26 minutes ago 4.98GB
|
||||
python 3.6 25bb503fe8c4 5 days ago 874MB
|
||||
ubuntu 18.04 6526a1858e5d 3 weeks ago 64.2MB
|
||||
```
|
||||
The images have been created but there is still no container. Note the value under IMAGE ID for the **dbm** REPOSITORY and enter it in the command below:
|
||||
|
||||
```bash
|
||||
> docker run -it <IMAGE ID for dbm REPOSITORY> /bin/bash
|
||||
```
|
||||
Once you create a new container from this image and execute the container, you can exit anytime by running:
|
||||
```bash
|
||||
root@<CONTAINER ID>:/app# exit
|
||||
```
|
||||
If the previous steps were done correctly, you should be able to see your container when running the following command:
|
||||
```bash
|
||||
> docker ps -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS
|
||||
7557af03538d 91e593533c96 "/bin/bash" 27 seconds ago Exited (0)
|
||||
```
|
||||
You can now start the container by using the CONTAINER ID above.
|
||||
```bash
|
||||
> docker start <CONTAINER ID>
|
||||
```
|
||||
Next, you will need to enter the container to execute the pipeline. Remember you can exit the container by typing **exit**
|
||||
```bash
|
||||
> docker exec -it <CONTAINER ID> bash
|
||||
```
|
||||
|
||||
### Running the main processing script
|
||||
|
||||
You are now ready to start processing data. Let’s test if we are set up properly by processing the sample data included in the Github repository. In this example, we will process files in the folder **sample_data**, and return the output to a folder on Desktop.
|
||||
|
||||
First you need to **move** the directory containing the data you want to process into the docker container in order to execute the pipeline. You can do this using:
|
||||
```bash
|
||||
> docker cp .../sample_data <CONTAINER ID>:/app/
|
||||
```
|
||||
Verify the location of the **sample_data** directory and its contents in the docker container:
|
||||
```bash
|
||||
> docker exec -it <CONTAINER ID> bash
|
||||
root@<CONTAINER ID>:/app# cd sample_data
|
||||
root@<CONTAINER ID>:/app/sample_data# ls
|
||||
subj01_timepoint01.mp4
|
||||
subj01_timepoint02.mp4
|
||||
subj02_timepoint01.mp4
|
||||
subj02_timepoint02.mp4
|
||||
root@<CONTAINER ID>:/app/sample_data# cd ..
|
||||
root@<CONTAINER ID>:/app#
|
||||
```
|
||||
This should put you back into the container root directory. This location contains the file
|
||||
**process_data.py**, and calling this script will process video and audio data using the given parameters.
|
||||
|
||||
In this example, calling the main processing script **process_data.py** will look like this:
|
||||
```bash
|
||||
root@<CONTAINER ID>:/app# python3 process_data.py
|
||||
--input_path sample_data/
|
||||
--output_path sample_output/
|
||||
--dbm_group facial acoustic movement speech
|
||||
--tr on
|
||||
```
|
||||
The parameters that need to be specified when calling the script are described below.
|
||||
|
||||
### Input path
|
||||
|
||||
The location of the files you want to process. If this path leads to a folder, all (supported) files will be processed, but it is also possible to have the path lead to a single file. The supported file formats are currently MP3 and WAV for audio files, and MP4 and MOV for video files.
|
||||
> **Note:** this path needs to be inside your docker container.
|
||||
|
||||
### Output path
|
||||
|
||||
The location of the folder where the processed data will be saved. If the folder does not already exist, the path will be generated with the output files saved within it. Similar to the input path, the output path will need to be located **inside** the docker container. Only after successfully running the processing script will you be able to move the output folder out of the container and into your system.
|
||||
|
||||
### DBM Group
|
||||
|
||||
The biomarker groups you want to calculate, including:
|
||||
|
||||
- **Facial, ** referring to measurements of facial behavior
|
||||
- **Acoustic** , referring to measurements of vocal acoustics
|
||||
- **Speech, ** referring to measurement of language characteristics
|
||||
- **Movement** , referring to motor and oculomotor functioning
|
||||
|
||||
For a list of all biomarkers within each group, see Section 5. If no group is passed, all possible biomarker groups will be calculated.
|
||||
|
||||
### Transcription
|
||||
|
||||
If the data passed contains speech, OpenDBM will transcribe and produce speech variables. ***However, the transcription itself will not be saved by default.*** If you are processing sensitive patient data, you should know that transcribed speech is still considered PHI. In case you are *sure* you’d like to save a copy of the speech transcription, you can turn this toggle **on**.
|
||||
|
||||
### Retrieving the output
|
||||
|
||||
If you navigate to the output path within the docker container you should see the output folder you passed earlier containing both a raw and derived output directory.
|
||||
```bash
|
||||
root@<CONTAINER ID>:/app# cd sample_output/
|
||||
root@<CONTAINER ID>:/app/sample_output# ls
|
||||
root@<CONTAINER ID>:/app/sample_output#
|
||||
raw_variables/ derived_variables/
|
||||
```
|
||||
You won’t be able to see these files in your system as long as they are in the container, so you need to run the following command to copy them back into your system.
|
||||
```bash
|
||||
root@<CONTAINER ID>:/app# exit
|
||||
> docker cp <CONTAINER ID>:/app/sample_output Desktop/sample_data
|
||||
```
|
||||
Your processed files will be located in the path Desktop/sample_data/sample_output. You’re all set with using OpenDBM! In the next section, we will go over how the outputs are structured.
|
||||
Reference in New Issue
Block a user